Seamless Workflow from Raw Logs to Production
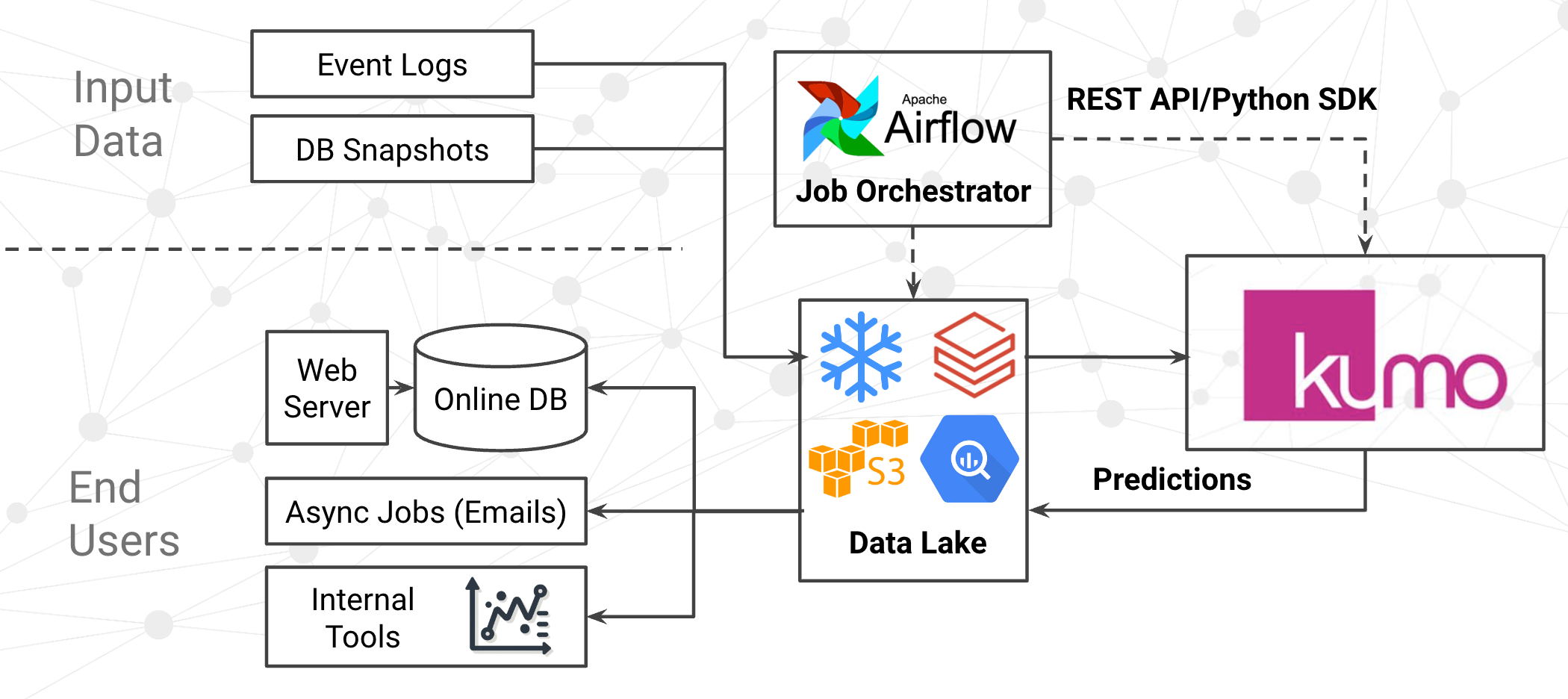
Kumo batch predictions integration with Snowflake + aws cloud + Airflow for online serving
Introduction:
In the dynamic world of data science, businesses are constantly seeking ways to do more with less. At Kumo, we understand the difficulties of deploying a new machine learning pipeline to production. In this document, we'll show you how to deploy one of Kumo's deep learning models to a consumer web application serving millions of users, highlighting the simplicity and ease of integration of Kumo with Snowflake, AWS cloud and Airflow, while meeting the scale, reliability, and operational requirements of an user-facing web service.
Key benefitsThe approach discussed here requires a one time setup cost of just 2 days, after which each new Predictive Query can be served online with one hour of work. This streamlined workflow presents a remarkable reduction in operational overhead compared to traditional online model-serving platforms, which may require building and distributing docker containers. By eliminating the necessity to fetch features online, this approach not only mitigates data discrepancy errors but also proves to be more cost-efficient, sparing organizations the expenses and resources associated with real-time feature retrieval. Moreover, the advantages extend beyond efficiency – embracing batch processing over real-time serving facilitates enhanced MLOps practices. Validation and rollback procedures become more straightforward when performed offline, allowing for meticulous testing and validation of models before deployment. This not only enhances the robustness of the predictive models but also provides a safety net for quick and effective rollback in the event of unforeseen issues, ensuring a more resilient and reliable predictive analytics pipeline.
Setup description
In this example, let's assume that you are working on an e-commerce app, and you are trying to predict the 5 best products to recommend to a user on the app's home page. Your goals is to recommend the products that the user is most likely to buy next, based on their past purchases and other activity on your website.
Step 1: Data Ingestion from Snowflake
Kumo can ingest data from a variety of data sources including Snowflake, S3, BigQuery, and Databricks. For simplicity, this example assumes your user activity logs are streamed directly into Snowflake, using something like the Snowflake Connector for Kafka. Since Kumo performs machine learning directly on the raw tables, there is no need to build and maintain complex workflows engineer features from these raw activity logs. Though, in the rare cases you need to apply pre-processing on your logs, you can easily create an "SQL View” directly inside Kumo.
Step 2: Fast Predictive Query Training
Kumo's interface allows you to train Predictive Queries with ease. You can use the UI if you want to get started quickly. You can also use the Python SDK, if you want to define your graph and Predictive Query as code and check it in to your repository. Regardless of your approach, Kumo will let you quickly iterate until you find the the problem formulation that delivers the best performance (in this case, recommendation performance).
Step 3: Batch Predictions orchestrated by Airflow
In this example you would want to generate a new set of product recommendations every day. To do this, you can write an Airflow job that launches a Batch prediction job through Kumo's REST API, and polls for it's completion. While this can be easily done in a couple dozen lines of code, Kumo also provides a Python SDK that lets you accomplish this entire process in a single line of code. When launching the Batch Prediction job, you only need to submit two pieces of information: (1) the predictive query ID and (2) the destination table in Snowflake. Kumo will take care of the rest, ingesting the most recent raw activity logs from Snowflake, and generating predictions based on this new information.
Step 4: Drift Detection and Validation
Upon completion of the Batch Prediction job, Kumo's REST API exposes stats and warnings from our automatic drift-detection systems. In your Airflow workflow, you can implement logic to optionally halt the workflow if the warnings exceed your acceptable thresholds. This is an easy way to prevent new predictions from reaching production if needed. Kumo puts control in your hands, making ML Ops, validation, and rollback procedures straightforward.
Step 5: Flexible Post-Processing in Snowflake
Often times, you may want to apply custom post-processing on the scores produced by the machine-learning model, such as joining against other tables, applying thresholds, or implementing other business logic. Since the output of Kumo's batch prediction job is a plain Snowflake table, you can easily write another Airflow job to perform this post-processing as the next step in your workflow. This step is optional if there no post processing is required on the model prediction output.
Step 6: Export to S3 and DynamoDB
Since your online web service cannot serve data directly from Snowflake, you need to export your predictions to a low-latency key-value store. The simplest approach is to first write an Airflow job that exports Snowflake tables to S3 as CSV files. Then, create a second Airflow job to upload the CSV file to a new DynamoDB table. Both of these jobs only require a couple lines of code -- the CSV export only requires a single Snowflake SQL command, and the DynamoDB upload can be performed with a single command in the AWS CLI.
Step 7: Swap the New Table into Production
Finally, you need to instruct your web service to read predictions from the table in DynamoDB. One option is to write the table name to a location that is accessible to your online services, such as Zookeeper or possibly a file on S3. Online services can be configured to read the table name from this location, and then fetch predictions from this table in DynamoDB. This way, whenever a new batch prediction job is successful, the table name gets updated, and all of your online services can read predictions from the new table. This "atomic swap" approach has operational benefits as well. In the case of a model quality incident (eg. low quality predictions being produced), the predictions can easily be "rolled back" by editing the table name to point to a known-good version.
Conclusion
By leveraging a straightforward one-time setup that encompasses Snowflake for seamless logs ingestion, the Kumo REST API for efficient batch prediction output, AWS DynamoDB for storing predictions intended for online serving, and Airflow for robust orchestration, users can power their web applications with Kumo’s Next Best Product recommendation. In addition to simplifying the deployment process, this batch-oriented approach enhances the overall efficiency and reliability of predictive analytics, making it an advantageous choice for businesses seeking optimal performance in their web applications.
Updated 2 months ago