Jobs
After creating your batch prediction workflow, you can kick off a batch prediction job. To do this, click on the Run Batch Prediction Job button on the right-hand side of the batch prediction workflow's detail page.
A modal window will appear where you can configure your batch prediction job settings.
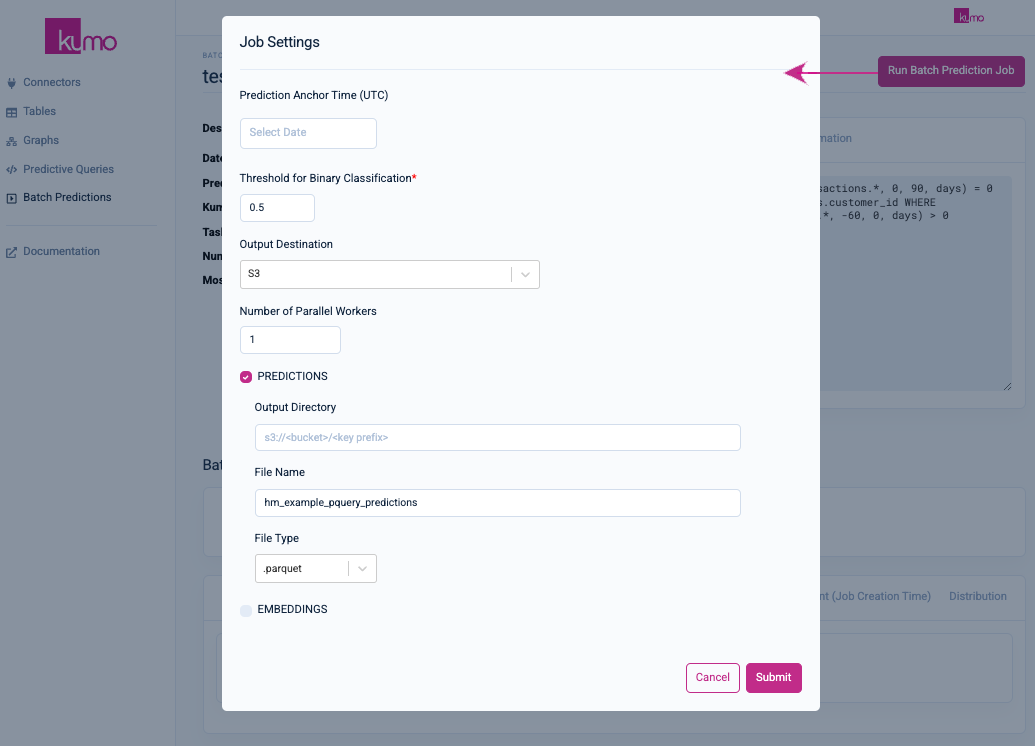
Batch Predictions Job Settings
You can configure the following settings for your batch prediction job:
Prediction Anchor Time
Temporal filtering is available for setting a custom prediction anchor time. Under "Prediction Anchor Time", you can set an optional starting date for your predictions in ISO 8601 format (e.g., 2024-02-27).
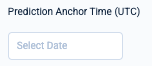
If left blank, Kumo will use the latest timestamp in the fact table specified by your PQuery's target formula.
Setting Per Prediction Type
You'll also need to specify some additional settings per your prediction type. For example, a binary classification task will require setting a threshold (e.g., 0.5) for determining the point at which an object is considered part of the target class.
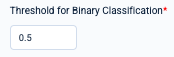
Your editable options (e.g., Threshold for Binary Classification) will depend on the type of prediction task at hand.
Output Destination
Specify the output destination for your predictions. Kumo allows you to export your batch predictions to the following output destinations: AWS S3, Snowflake, BigQuery, or local download.
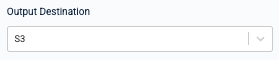
S3
Kumo allows exporting batch predictions as a single CSV or Parquet file, or as a partitioned Parquet file. To export as a partitioned Parquet file, please use the special file name {{PARTITION}}, when specifying the output file path. This {{PARTITION}} file name will be replaced by the name of the partition file, such as part_000, though the exact filename is subject to change. The size of each partition will be on the order of hundreds of megabytes.
Snowflake
To export to Snowflake, select your Snowflake connector and input the name of the table. If this table already exists, Kumo will delete the existing rows in the table before writing the new predictions.
Note: The user account that you used to create the Snowflake connector must have permissions to create tables in Snowflake.
If you're using Snowflake Secure Share, Kumo will create a secure view with the predictions table/database, which the Kumo POC will then use to share the predictions with you securely via secure share.
BigQuery
To export to BigQuery, select your BigQuery connector and input the name of the table. If this table already exists, Kumo will append predictions to this table (not replace it).
Note: The user account that you used to create the BigQuery connector must have permissions to create tables in your BigQuery data warehouse.
Local Download Only
To download batch predictions to your desktop, select Local Download Only from the "Output Destination" drop-down menu. You can download a sample of the outputs, up to 1 GB in size.
Number of Parallel Workers
Under "Number of Parallel Workers", you can specify the number of workers (up to 4) that simultaneously work together in generating your batch predictions.
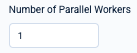
By default, a single worker works on a prediction task; increasing the number of workers, especially for large datasets, can significantly reduce the time it takes to generate predictions.
Batch Prediction Output Type
Kumo allows you to output your batch predictions to two types:
- Predictions - for the pQuery's target formula (after filters are applied)
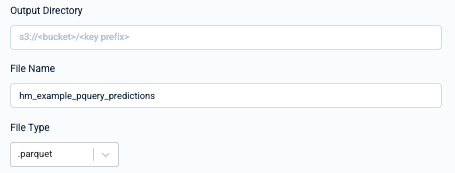
- Embeddings - numerical vectors that represent each entity referred to in the underlying pQuery, encoding information about how similarly different entities behave.
You'll need to either specify an output directory (for S3) or a table name (for Snowflake/BigQuery), depending on your output destination.
If you select "Local Download Only," you will be able to download a sample of the outputs (up to 1GB). Also, you'll need to specify a file type for your prediction outputs— either Parquet or CSV file format.
You can later download a sample batch prediction output—even if you choose to write predictions to another data source.
The resulting table will contain a column for the entity id, columns for predicted values or embeddings, and a timestamp column if relevant.
Saving and Running Your Batch Prediction Job
Click on the Submit button to save your settings and kick off your batch prediction job.
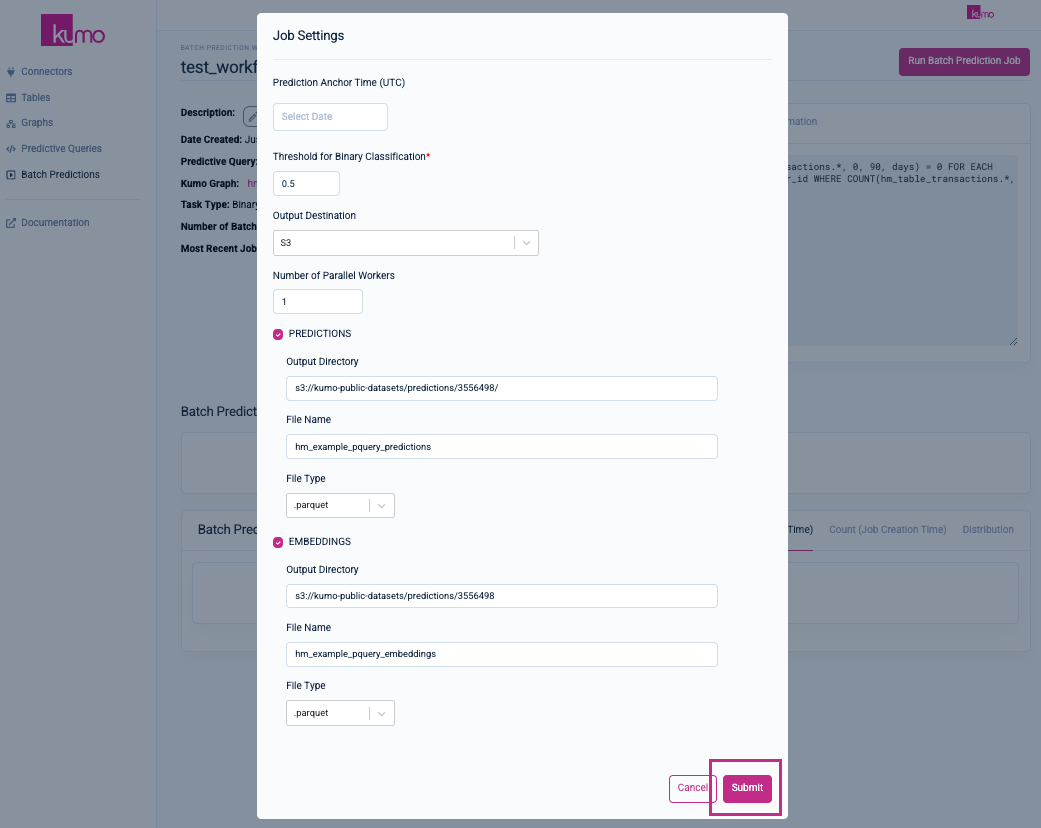
You'll be routed to your batch prediction job's detail page, where you can monitor the progress of your batch prediction job.
Updated 2 months ago