Fraud Detection Demo
This demo will demonstrate how to use Kumo to detect fraudulent credit card transactions.
Prerequisites
- Sign Up for a Free Trial: If you haven't already, sign up for a free trial at Kumo Free Trial.
- [SPCS Only]: Ensure the Kumo app is installed and started. If you haven't already installed or started Kumo, follow the instructions on how to install Kumo.
What You Will Learn in This Demo
You will learn how to use Kumo's GNNs to predict fraudulent transactions. We will use a dataset created by the Sparkov Fraud Data Generator. This dataset generator simulates credit card transactions according to several real-world fraud patterns, such as:
- A credit card being stolen - multiple fraudulent transactions happening in quick succession
- A fraudulent merchant - a bad merchant making many fake transactions
As you will see in this tutorial, the Kumo Graph Neural Network is highly effective at learning these temporal and relational patterns, resulting in a model with extremely high accuracy.
The dataset is organized into four main tables:
- Customers: Contains information about ~1000 customers and their location
- Merchants: Contains information about ~700 merchants and their location
- Transactions: Contains 1 million transactions spanning over about 18 months
- Fraud Reports: Contains 14 thousand customer fraud reports, half of which have been confirmed to be valid according the fraud operations team
While this dataset is intentionally kept small for demonstration purposes, the Kumo platform can easily scale to datasets that are thousands of times larger.
Step 0 [SPCS Only]: Upload Data to Your Snowflake Account
See details
Follow these steps to upload the H&M data:
-
Log into your Snowflake account.
-
Run these commands to load the dataset from Kumo's public S3 bucket into your Snowflake account:
-- This script loads data generated by the Sparkov Fraud Data Generator, from a public bucket on S3. -- https://github.com/namebrandon/Sparkov_Data_Generation -- Define variables for database and schema SET DATABASE_NAME = 'KUMO_DB'; SET SCHEMA_NAME = 'FRAUD'; -- Create database/schema if not exists CREATE DATABASE IF NOT EXISTS IDENTIFIER($DATABASE_NAME); SET FULL_SCHEMA_NAME = CONCAT($DATABASE_NAME, '.', $SCHEMA_NAME); CREATE SCHEMA IF NOT EXISTS IDENTIFIER($FULL_SCHEMA_NAME); -- Create or replace the external stage CREATE OR REPLACE STAGE kumo_fraud_stage URL='s3://kumo-public-datasets/credit_card_fraud/' FILE_FORMAT = (TYPE = PARQUET); -- Section: Transactions Table -- Create the transactions table SET TRANSACTIONS_TABLE_NAME = CONCAT($FULL_SCHEMA_NAME, '.transactions'); CREATE TABLE IF NOT EXISTS IDENTIFIER($TRANSACTIONS_TABLE_NAME) (trans_date_trans_time TIMESTAMP, cc_num NUMBER(38,0), merchant VARCHAR, trans_num VARCHAR, amt NUMBER(38, 2)); -- Copy data into the transactions table COPY INTO IDENTIFIER($TRANSACTIONS_TABLE_NAME) FROM ( SELECT $1:trans_date_trans_time::TIMESTAMP, $1:cc_num::NUMBER(38,0), $1:merchant::VARCHAR, $1:trans_num::VARCHAR, $1:amt::NUMBER(38, 2) FROM @kumo_fraud_stage/transactions.parquet ) FILE_FORMAT = (TYPE = PARQUET) ON_ERROR = ABORT_STATEMENT; -- Section: Customers Table -- Create the customers table SET CUSTOMERS_TABLE_NAME = CONCAT($FULL_SCHEMA_NAME, '.customers'); CREATE TABLE IF NOT EXISTS IDENTIFIER($CUSTOMERS_TABLE_NAME) (cc_num NUMBER(38,0), first VARCHAR, last VARCHAR, gender VARCHAR, street VARCHAR, city VARCHAR, zip NUMBER(38,0), lat FLOAT, long FLOAT, city_pop NUMBER(38,0), job VARCHAR, dob DATE); -- Copy data into the customers table COPY INTO IDENTIFIER($CUSTOMERS_TABLE_NAME) FROM ( SELECT $1:cc_num::NUMBER(38,0), $1:first::VARCHAR, $1:last::VARCHAR, $1:gender::VARCHAR, $1:street::VARCHAR, $1:city::VARCHAR, $1:zip::NUMBER(38,0), $1:lat::FLOAT, $1:long::FLOAT, $1:city_pop::NUMBER(38,0), $1:job::VARCHAR, $1:dob::DATE, FROM @kumo_fraud_stage/customers.parquet ) FILE_FORMAT = (TYPE = PARQUET) ON_ERROR = ABORT_STATEMENT; -- Section: Merchants Table -- Create the merchants table SET MERCHANTS_TABLE_NAME = CONCAT($FULL_SCHEMA_NAME, '.merchants'); CREATE TABLE IF NOT EXISTS IDENTIFIER($MERCHANTS_TABLE_NAME) (merchant VARCHAR, category VARCHAR, merch_lat FLOAT, merch_long FLOAT); -- Copy data into the merchants table COPY INTO IDENTIFIER($MERCHANTS_TABLE_NAME) FROM ( SELECT $1:merchant::VARCHAR, $1:category::VARCHAR, $1:merch_lat::FLOAT, $1:merch_long::FLOAT FROM @kumo_fraud_stage/merchants.parquet ) FILE_FORMAT = (TYPE = PARQUET) ON_ERROR = ABORT_STATEMENT; -- Section: Fraud Reports Table -- Create the fraud reports table SET FRAUD_REPORTS_TABLE_NAME = CONCAT($FULL_SCHEMA_NAME, '.fraud_reports'); CREATE TABLE IF NOT EXISTS IDENTIFIER($FRAUD_REPORTS_TABLE_NAME) (report_time TIMESTAMP, trans_num VARCHAR, is_real_fraud NUMBER(38,0)); -- Copy data into the transactions table COPY INTO IDENTIFIER($FRAUD_REPORTS_TABLE_NAME) FROM ( SELECT $1:report_time::TIMESTAMP, $1:trans_num::VARCHAR, $1:is_real_fraud::NUMBER(38,0) FROM @kumo_fraud_stage/fraud_reports.parquet ) FILE_FORMAT = (TYPE = PARQUET) ON_ERROR = ABORT_STATEMENT; -
Inspect the tables:
While the data is being uploaded, you can continue with Step 1 and connect your database to Kumo. After that, return to Snowflake to inspect the tables using the following queries:
-- View data from the transactions table SELECT * FROM IDENTIFIER($TRANSACTIONS_TABLE_NAME) LIMIT 10; -- View data from the merchants table SELECT * FROM IDENTIFIER($MERCHANTS_TABLE_NAME) LIMIT 10; -- View data from the customers table SELECT * FROM IDENTIFIER($CUSTOMERS_TABLE_NAME) LIMIT 10; -- View data from the fraud reports table SELECT * FROM IDENTIFIER($FRAUD_REPORTS_TABLE_NAME) LIMIT 100;
Step 1: Set Up Your Connector
Setting up the connector ensures that Kumo can access your data, enabling seamless data integration for model training.
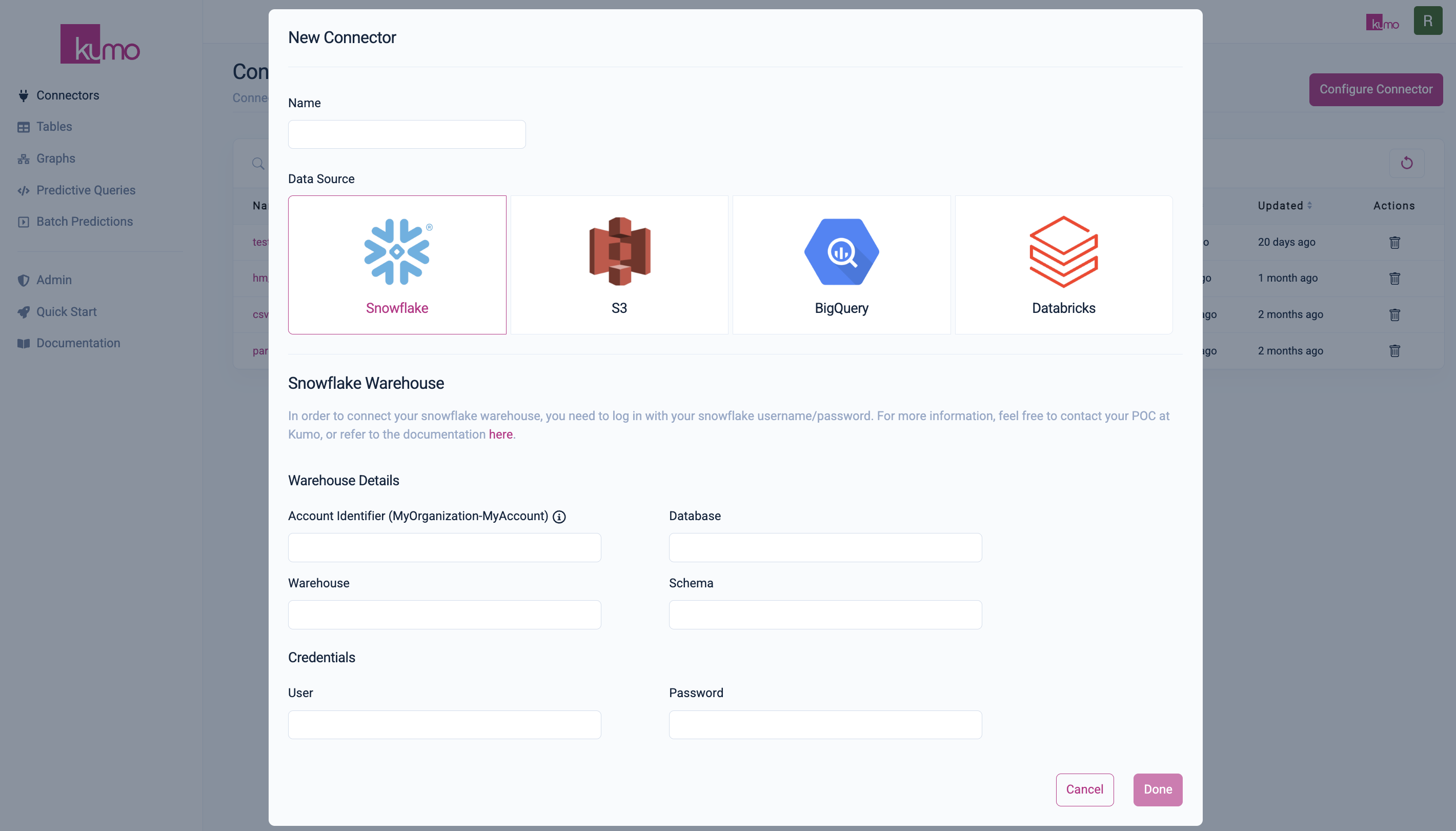
-
Open Connector Configuration:
- In the left-hand menu, click on
Connectors. - Click
Configure Connectorto open the "New Connector" modal.
- In the left-hand menu, click on
-
Create a New Connector:
i. Provide a name for your new connector (e.g.,
fraud_connector).ii. Choose your data source:
-
For Snowflake, enter the following details:
- Account Identifier:
ORGNAME-ACCOUNT_NAME. Find your account details. - Database: The database where your data exists. Ensure your user has
USAGEprivileges. If you followed Step 0, it will beKUMO_DB. - Warehouse: The warehouse to process data. Ensure your user has
USAGEprivileges. - Schema Name: The schema to load tables from. Your user should have
USAGEandSELECTprivileges, andCREATE TABLEfor writing back predictions. If you followed Step 0, it will beFRAUD. - User: Your username for Snowflake.
- Password: Your password for Snowflake.
- Account Identifier:
-
For S3:
- In the S3 Path textbox, enter:
s3://kumo-public-datasets/credit_card_fraud/. - Click the
Validatebutton to see all files within the directory.
- In the S3 Path textbox, enter:
-
For other data sources: See Data Connectors.
iii. Click
Doneto save the connector. -
Step 2: Register Table Schema
Now that you've set up your connector, it's time to register the Fraud dataset within Kumo. This step defines how columns are later encoded for the model and sets the requirements for the graph schema registration by defining the primary keys of each table.
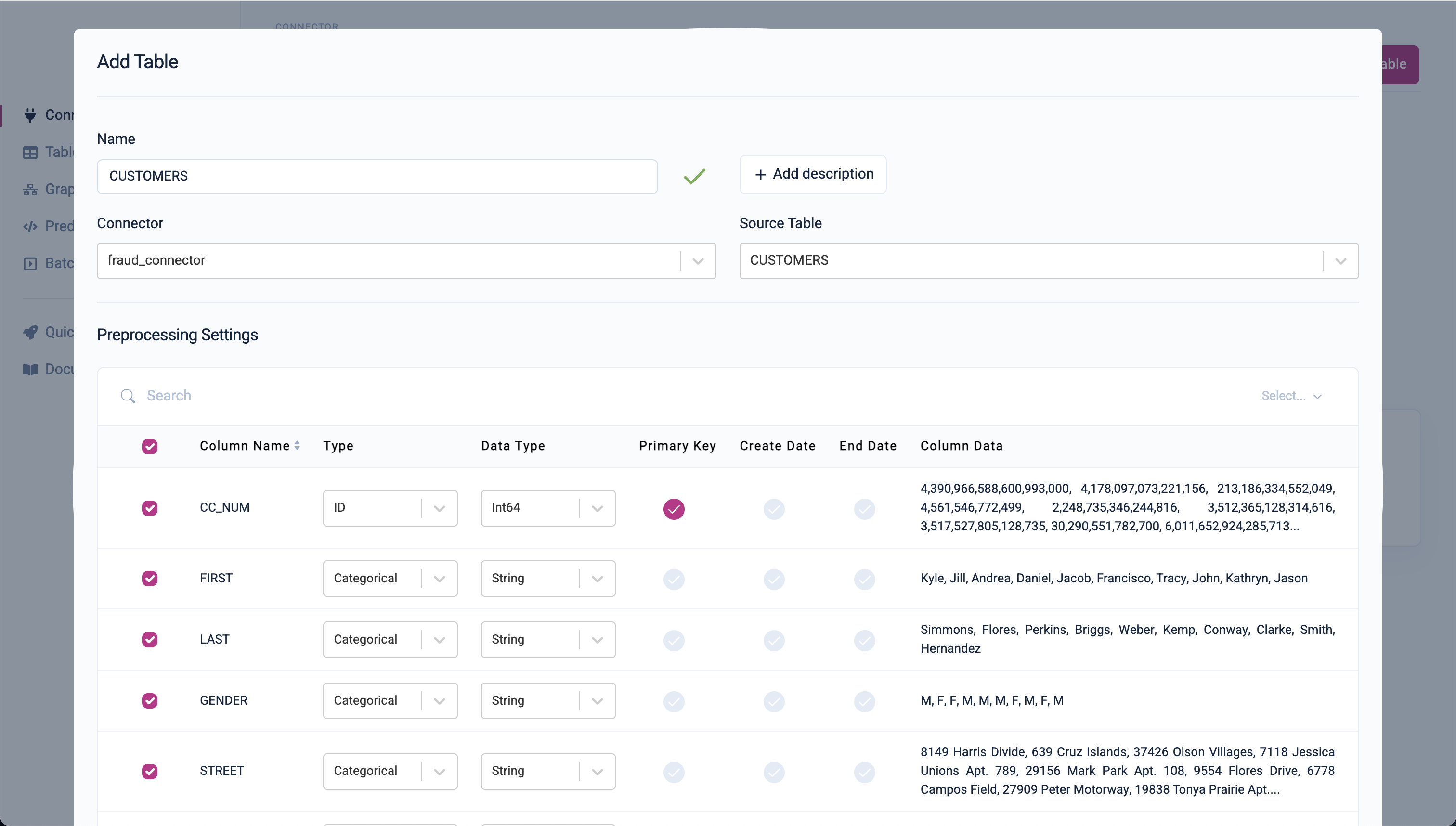
-
Navigate to Tables Overview:
- In the left-hand menu, click on
Tables.
- In the left-hand menu, click on
-
Add Data Tables (Customers, Articles, Transactions):
Follow the steps for each table:
-
Click
Add Table. -
Set the table name.
-
Select the appropriate connector (e.g.,
fraud_connector). -
Choose the respective table from your data source.
-
Wait for column types to be inferred based on sample statistics. If this takes too long, which can happen in SPCS deployments if the warehouse you are using is busy, skip the inferring and set the column types manually. Follow these steps:
-
Check the type of each column: The type of a column refers to how the data is later encoded. Kumo supports preprocessing for the following generic types:
- Numerical: Integers and floats where the ordering of numbers from lower to higher values has semantic meaning (e.g., product price, percentage discount).
- Categorical: Boolean values or string values typically only a single token in length, with limited semantic meaning, and up to 4000 unique values (e.g., premium subscription status).
- Multi-categorical: Comma-separated variable length lists of categorical values (e.g., a list of product attributes or categories).
- ID: Columns the correspond to primary or foreign keys in a relational schema. (e.g., customer ID, product group number).
- Text: String values with multiple tokens in length, where the content has semantic meaning (e.g., product description).
- Timestamp: String or format-specific date/timestamp values (preferably ISO 8601). Ensure date/time format is valid.
- Embedding: Lists of floats, all of equal length; typically the output of another AI model.
-
Check the data type: This refers to the underlying data type. This is especially relevant for connecting tables later, as only columns with the same type can be connected via a Primary/Foreign key link. No modification is needed for data types for the H&M dataset.
-
Set the primary key: This is the unique identifier column of a table and is used later within the Primary/Foreign key connection.
-
Set a create date: For tables that correspond to real-world events (such as transactions), this is the time that the even took place in the real world. Kumo uses this to automatically prevent data leakage during training time, which is a very common mistake when building models by hand.
-
-
Before saving, please verify if all properties are set correctly:
-
Customers: Set the Primary Key to
CC_NUMwith Type =ID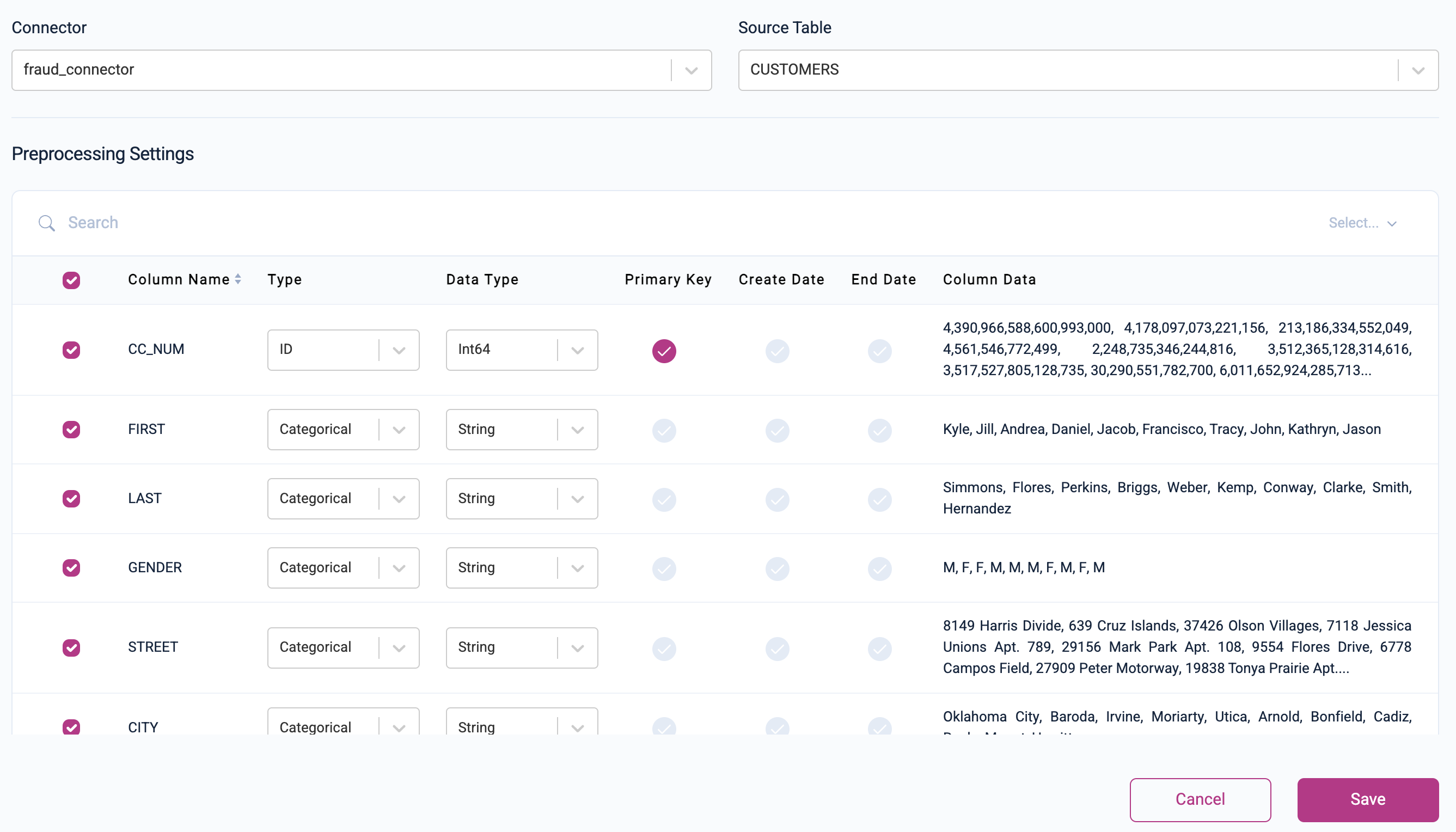
-
Merchants: Set the Primary Key to
MERCHANTwith Type =ID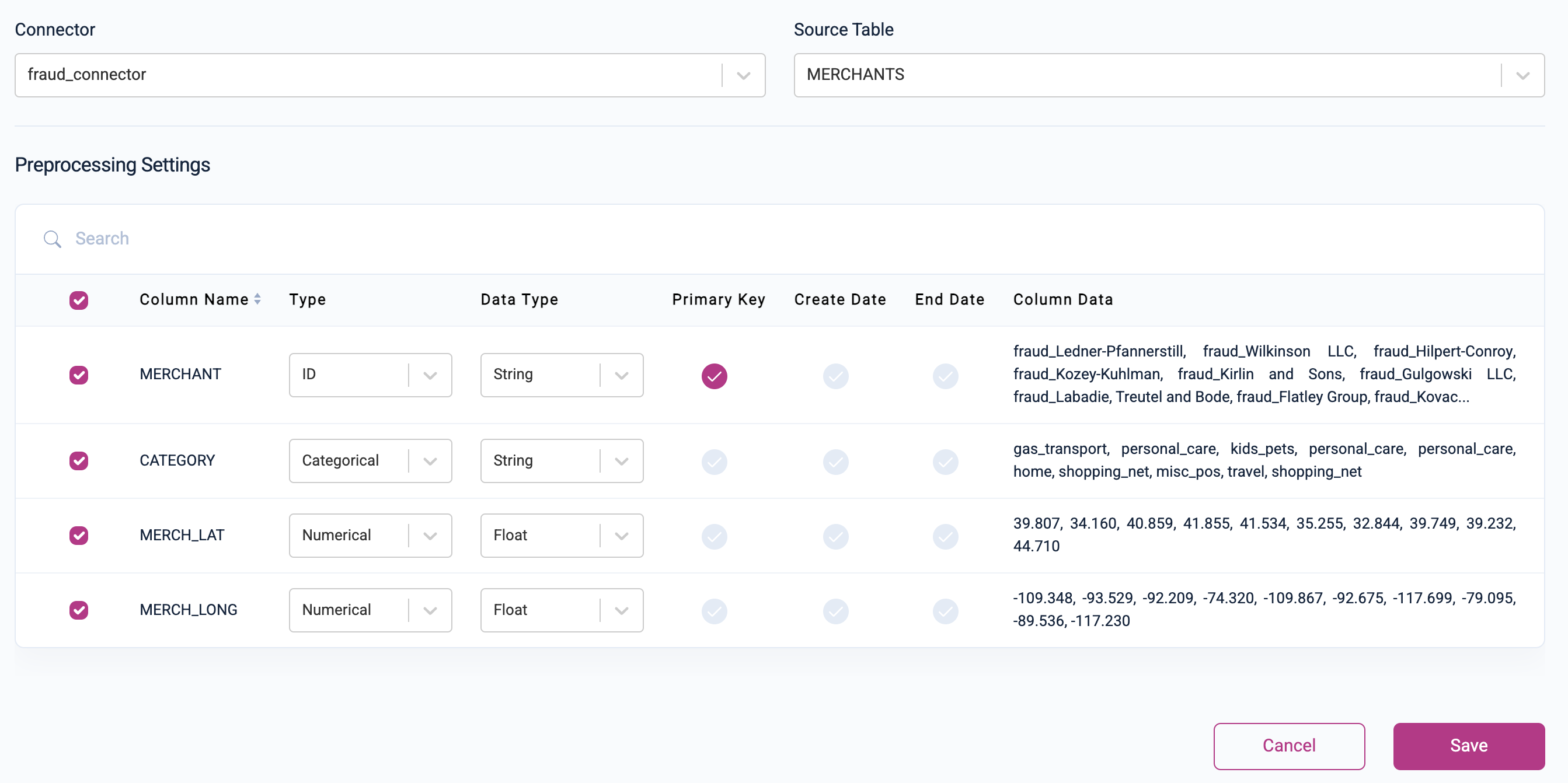
-
Transactions: Change the Type of
CC_NUMandMERCHANTtoID, because they are foreign keys into other tables. SetTRANS_NUMto be the Primary Key, with Type =IDas well. SetTRANS_DATE_TRANS_TIMEas the Create Date.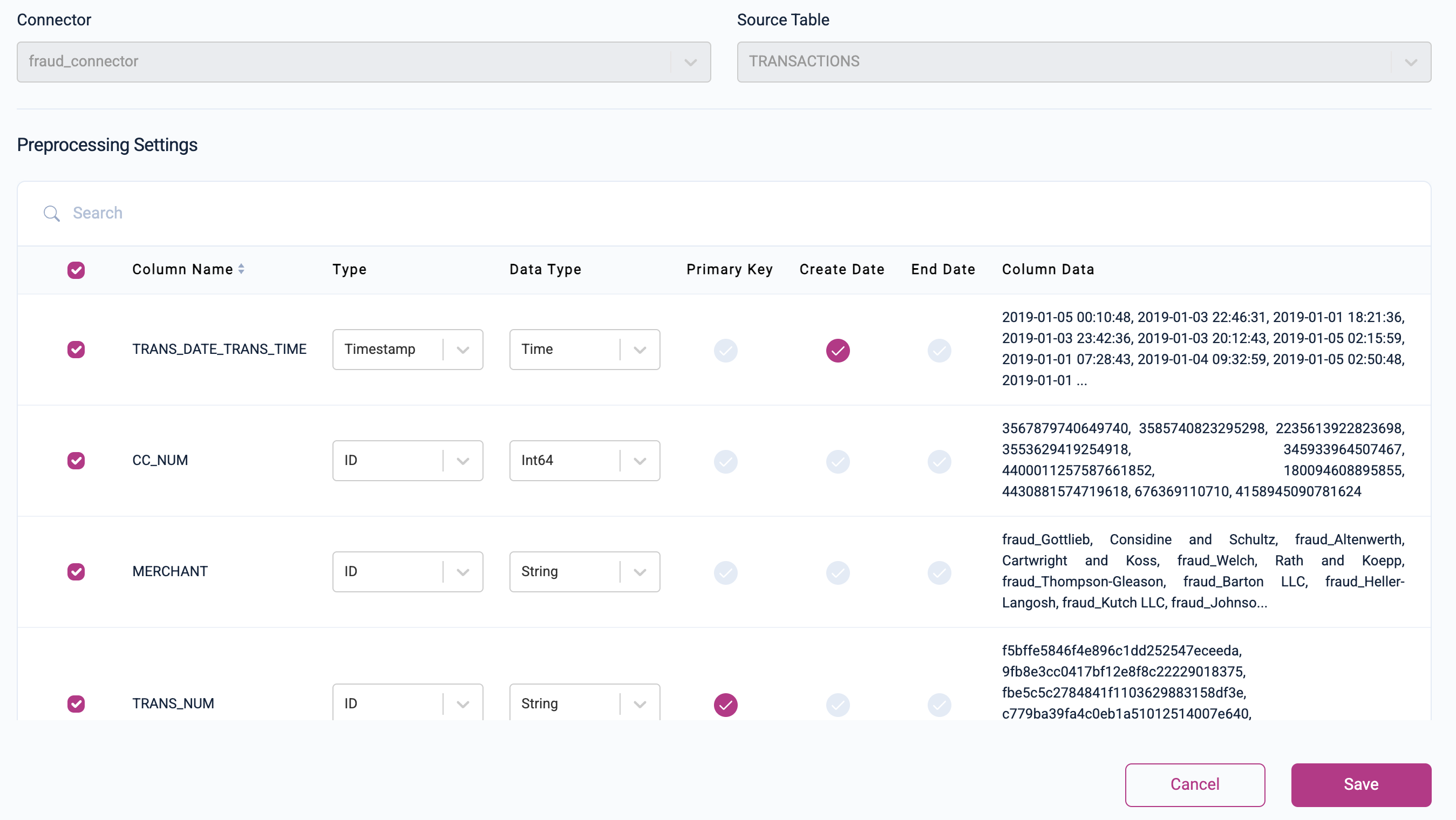
-
Fraud Reports: Change the type of
TRANS_NUMto ID because it is a foreign key into theTRANSACTIONStable. SetREPORT_TIMEas the Create Date.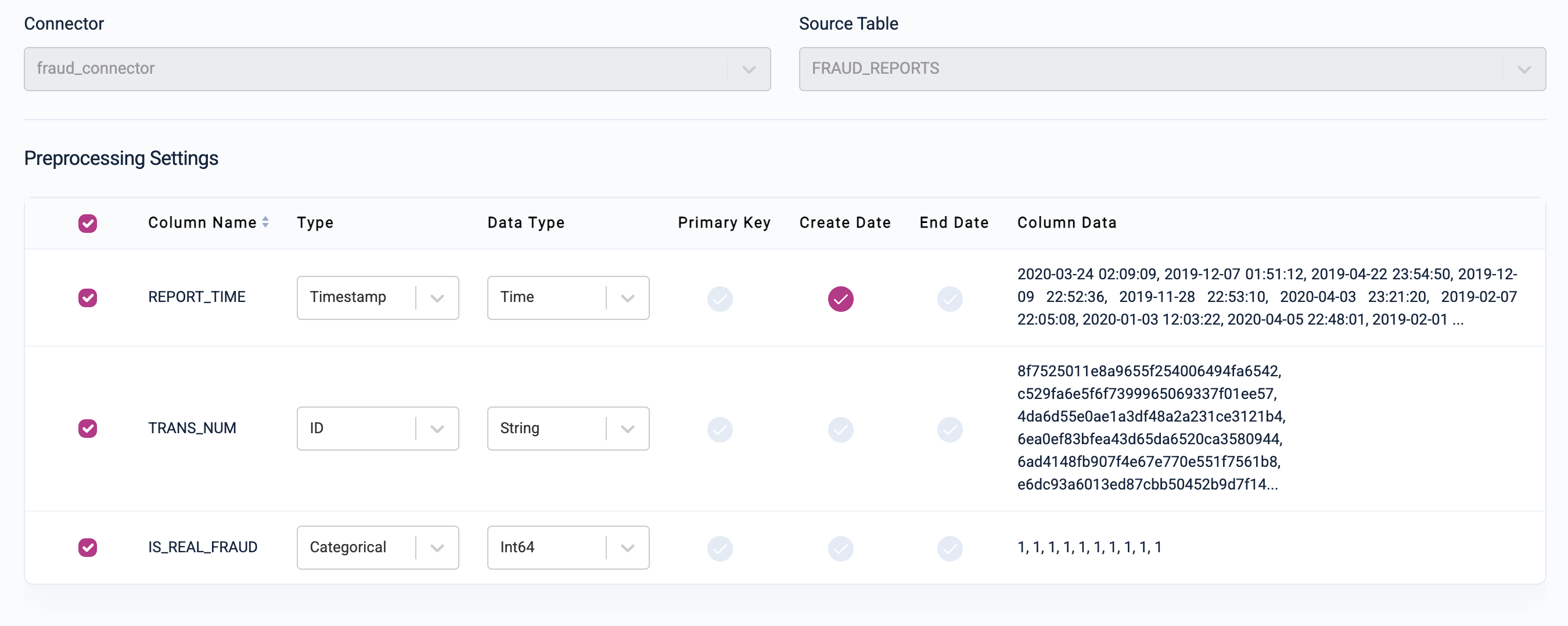
-
-
Click
Saveto save each table.
-
Step 3: Create a Graph Schema
Now that your tables are registered, it's time to define the graph schema, which specifies how your data tables are connected. This step is crucial for using Graph Neural Networks (GNNs) effectively.
-
Navigate to Graph Setup:
- In the left-hand menu, click on
Graphs.
- In the left-hand menu, click on
-
Create a New Graph:
i. Click
Create Graphin the top right-hand corner.ii. Provide Graph Details:
- On the "Graph Setup" page, provide a name for your new graph (e.g.,
fraud_graph).
iii. Select Tables:
- Select the
TRANSACTIONS,CUSTOMERS,FRAUD_REPORTS, andMERCHANTStables by checking the respective boxes.
iv. Configure Graph Links:
- Click the
Nextbutton on the top right-hand corner. - Kumo will automatically detect and suggest linkages.
- Verify the linkages:
- Ensure
CC_NUMinCUSTOMERSis linked toCC_NUMinTRANSACTIONS. - Ensure
MERCHANTinMERCHANTSis linked toMERCHANTinTRANSACTIONS. - Ensure
TRANS_NUMinFRAUD_REPORTSis linked toTRANS_NUMinTRANSACTIONS.
- Ensure
- Click the
Confirm Groupbutton for both column groups.
v. Complete Graph Creation:
- Click on the
Complete Graph Creationbutton on the top right-hand corner.
- On the "Graph Setup" page, provide a name for your new graph (e.g.,
With this, all preparation is done. You should see the following graph now:
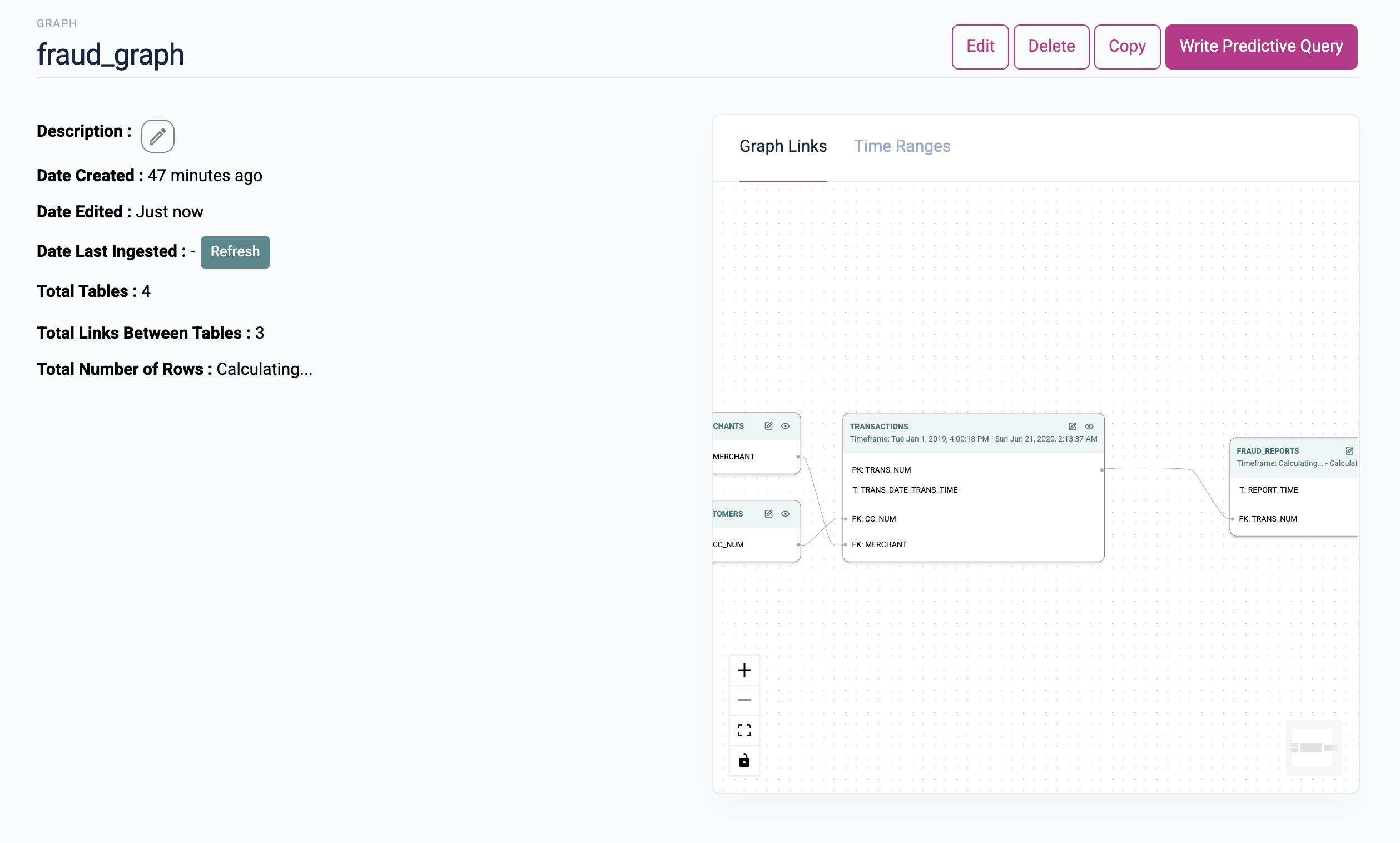
Step 4: Train Your First Model via PQL
After specifying the graph, you can train a model using Kumo's Predictive Query Language (PQL). PQL helps specify the training table, defining the target and the entity for which you want to make predictions. In our case, we want to predict for each customer which three articles they are most likely to purchase in the next 30 days. For this:
-
Open Predictive Query Creation:
- Click on
Write Predictive Queryin the top right-hand corner.
- Click on
-
Train Model via a Predictive Query:
i. Provide a name for your predictive query (e.g.,
cc_fraud).ii. Select the graph you created earlier from the drop-down menu.
iii. Specify PQuery:
- In the PQuery text area, insert the following PQL statement to predict the probability that a given transaction is fradulent.
The query defines how the training data is (automatically) generated. In this example, Kumo will generate a training table of positive and negative examples that are used to train the model. Positive examples are define to be transactions that were reported for fraud within 7 days after the transaction took place.
PREDICT COUNT(FRAUD_REPORTS.* WHERE FRAUD_REPORTS.IS_REAL_FRAUD = 1, 0, 7, days) >= 1 FOR EACH TRANSACTIONS.TRANS_NUM
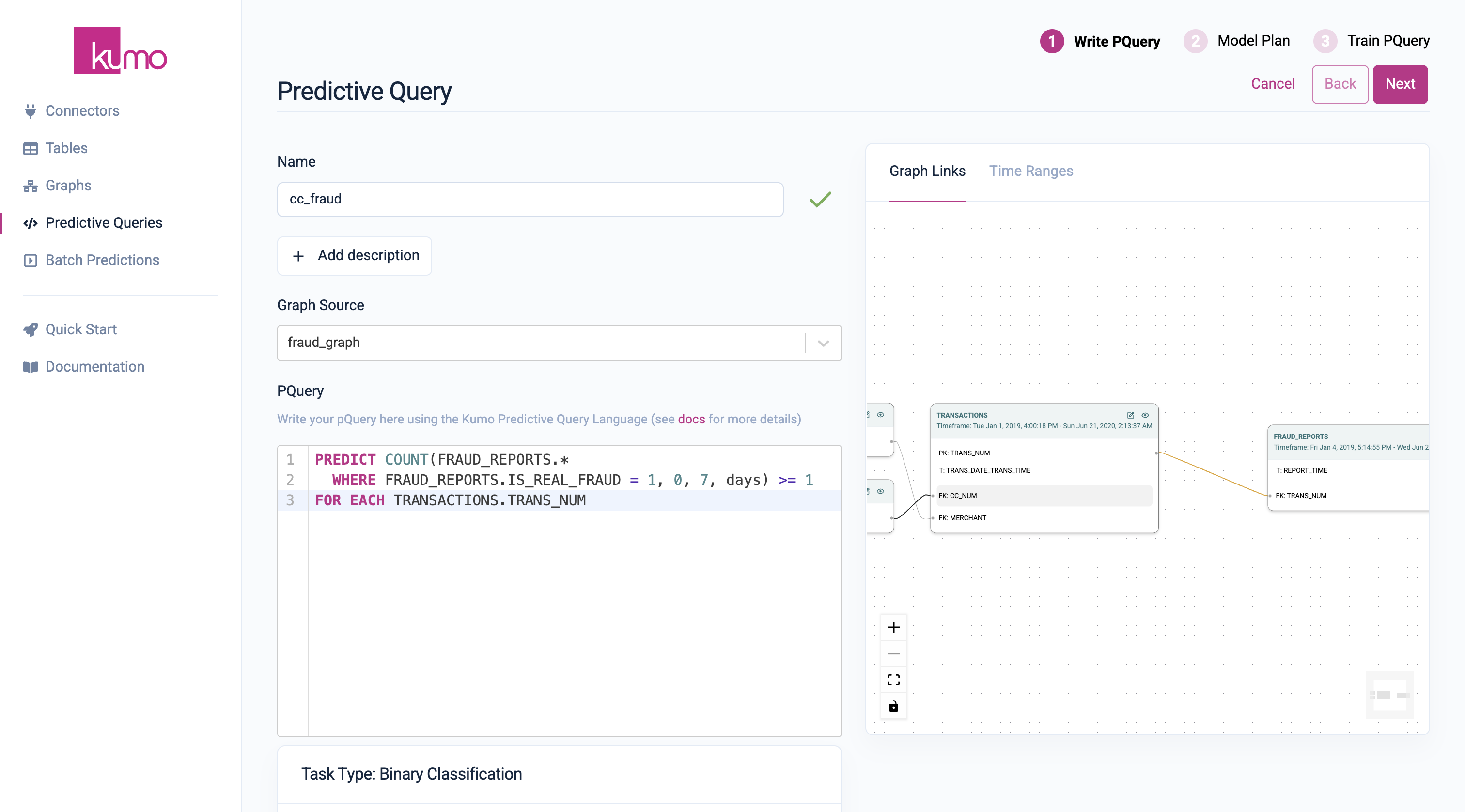
iv. Click
Nextto specify the Model Planner.- Since this fraud dataset has extremely heavy class imbalance (fraud is an extremely rare event), we need to tell the GNN to pay more attention to the (rare) positive examples. In order to do this, we can set majority_sampling_ratio to
100and tune_metric toauprc.
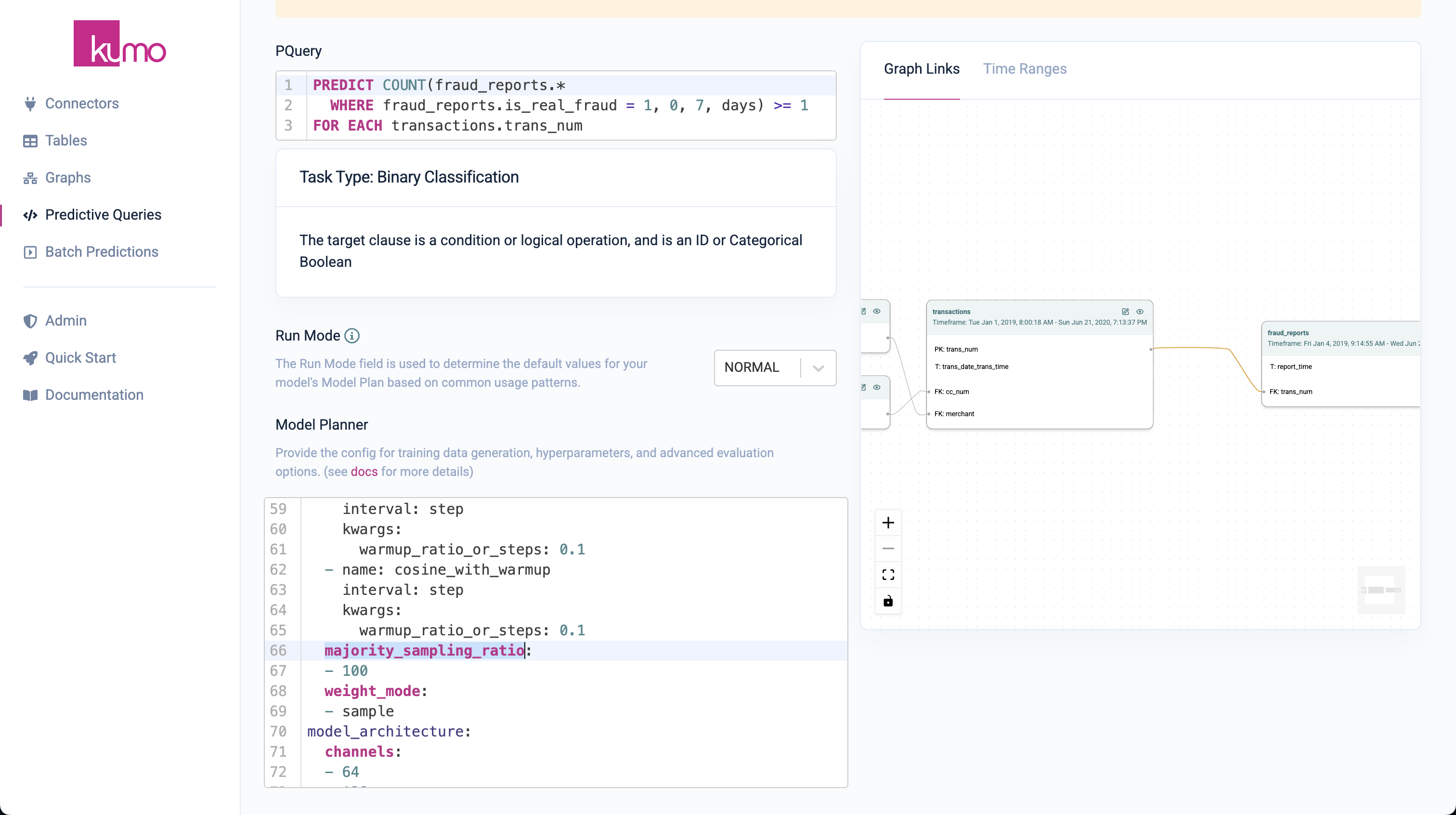
v. Click
Save and Train. - In the PQuery text area, insert the following PQL statement to predict the probability that a given transaction is fradulent.
🏆 Great work! You are training your first model. This can take a few minutes as we ingest the data into the system, encode the columns, build the computation graph, train models, and evaluate the models. You can follow the process as we will show training table statistics and metric curves such as loss curves. When the training is complete, take a look at the results by:
-
Checking out the evaluation metrics within the evaluation tab.
-
Inspecting the holdout set either via the
Downloadbutton or via the shown SQL command within Snowflake for SPCS deployments . -
Explore example predictions also in our explorer tab, which shows you the specific predictions made by the model and how they match the actual outcomes.
Conclusion
🚀 You have now successfully created and trained your first predictive model using Kumo. Here is a summary of what we have covered:
- Set Up Your Connector: Connected your data source to Kumo.
- Register Table Schema: Defined the table schema
- Create Your Graph: Defined the relationships between tables.
- Create Your PQuery: Wrote and trained models via a predictive query to make predictions.
Next, you can start training models on your data. To learn how to write a PQuery, take a look at our PQuery Tutorial. Additionally, you can check out information on how to create batch predictions, or how to productionize your model.
Updated 3 months ago