Evaluation
Verifying the accuracy of your Kumo pQuery results.
To ensure that your predictions are good enough to make a positive impact to your organization, you should verify that your predictive query's performance metrics are inline with expectations. Kumo provides you with a myriad of instruments for gauging the efficacy of your predictive query in production using unseen data.
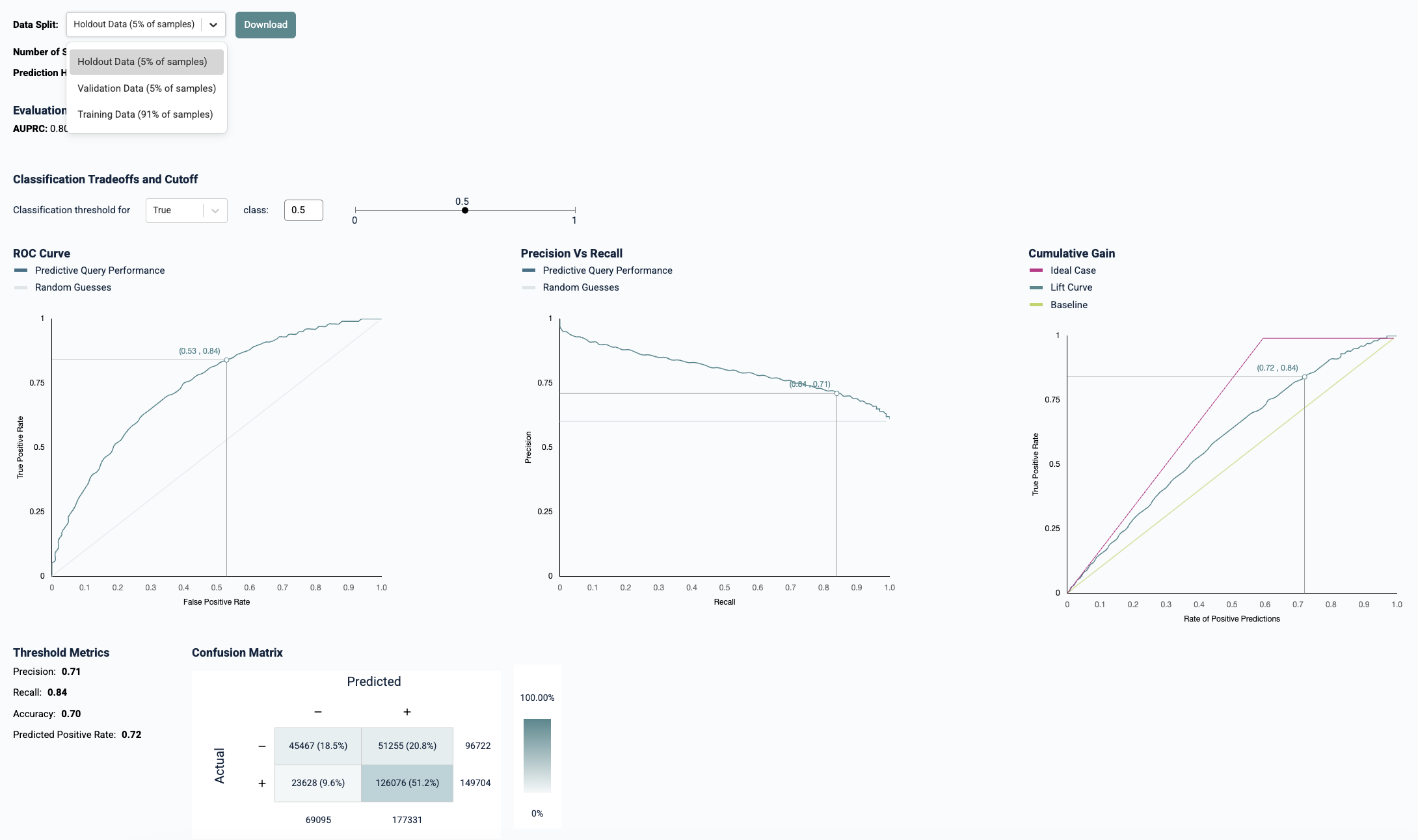
Kumo performs an evaluation that checks your predictive query's accuracy against the most recent time period in your available historical data (e.g. the "holdout set"), without using any of the data from that recent time period as input into the prediction process. You can click on the "Evaluation" tab on a particular predictive query's detail page to analyze its performance.
By default, Kumo use the most recent time window to create your predictive query's evaluation metrics. The time window length is defined by your predictive query—for example, if you're making predictions for the next 30 days, the time window in this evaluation period will be the most recent 30 days of historical data. The rest of the data is used for training. You can customize these values in your model plan, when creating or editing your predictive query.
For more about evaluation metrics, please see the Kumo FAQ for evaluating your model's prediction results.
Validation Data Split and Evaluation Metrics
Kumo starts the training process by partitioning your historical training examples into three sets:
- Holdout Data Split: The most recent timeframe(s) of training examples, used for evaluating the model on how well it generalizes to future unseen data, and entirely kept out of the model training process.
- Validation Data Split: The second-to-most recent timeframe(s) of training examples, used during the neural architecture search experimentation process for determining which model coming out of the experimentation process is best for promoting to an evaluation on the holdout data split.
- Training Data Split: All remaining earlier timeframe(s) of training examples, used for training each of the models created during the experimentation process.
During the training process, Kumo automatically defines a search space of potential GNN model architectures and hyper-parameters, followed by an intelligent selection of a subset of specific architecture and hyper-parameter configurations to run experiments with. Each experiment is trained on the training data split, then evaluated on the validation data split.
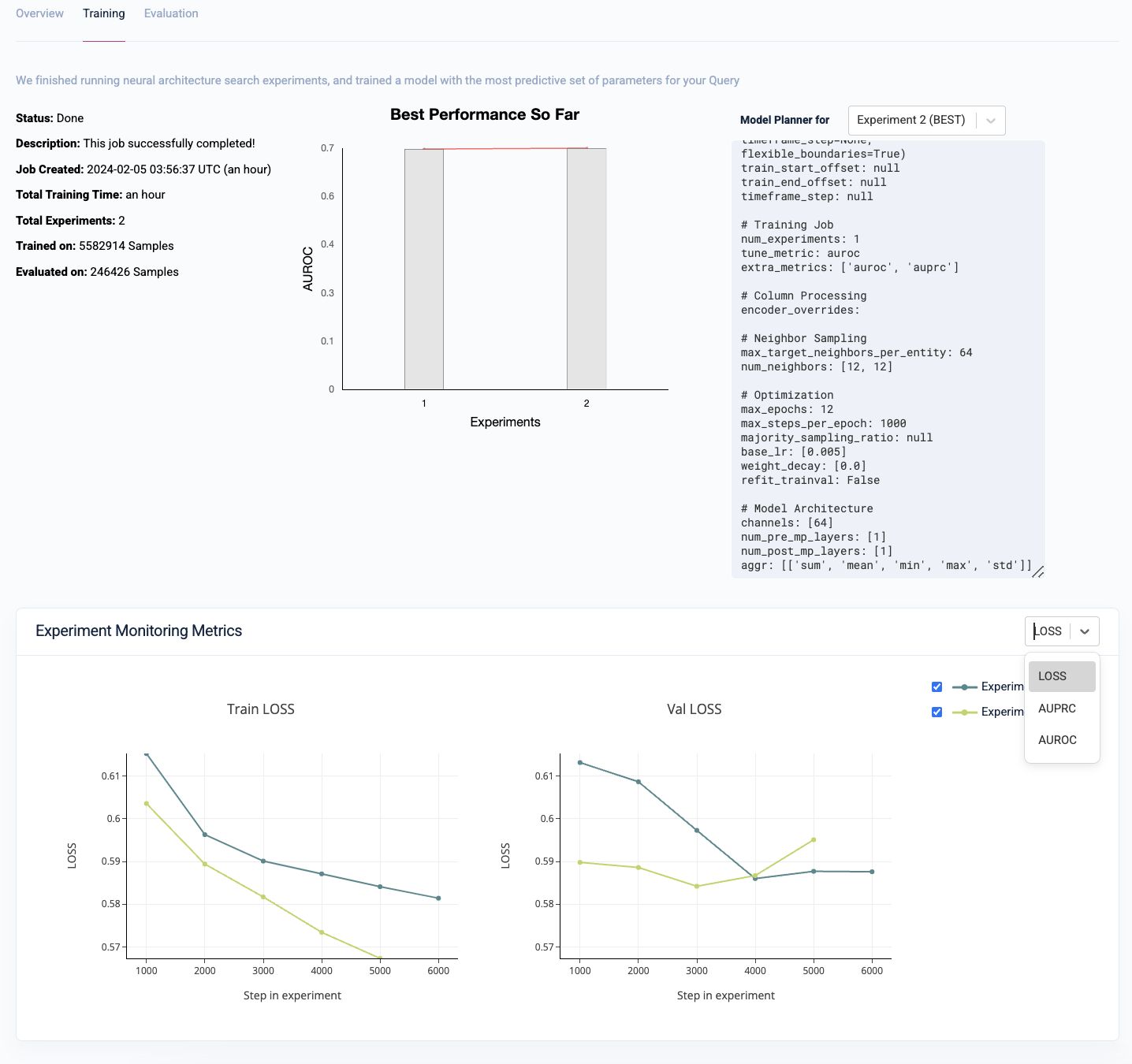
The single winning experiment (i.e., the winning model architecture and hyper-parameter configuration on the validation data split) is then fully evaluated on the holdout data split. The results of this experiment are then used to create your predictive query's evaluation metrics.
Updated 2 months ago