Regression
For numerical predictions and labels, Kumo provide metrics for measuring the numerical distance between the actual and predicted values.
Mean Absolute Error (MAE)
MAE is calculated by:
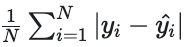
where yi is the ith label and ŷi is the ith predicted value.
Mean Squared Error (MSE)
MSE is calculated by:
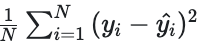
MSE focuses more on "how wrong" the prediction is. A prediction that is very far from the label will contribute more to increasing the MSE than the MAE.
Root Mean Square Error (RMSE)
RMSE is calculated by:
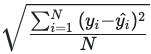
This score is in the same scale as the target and can be used even if a label is 0 or near 0.
Mean Absolute Percentage Error (MAPE)
MAPE is calculated by:
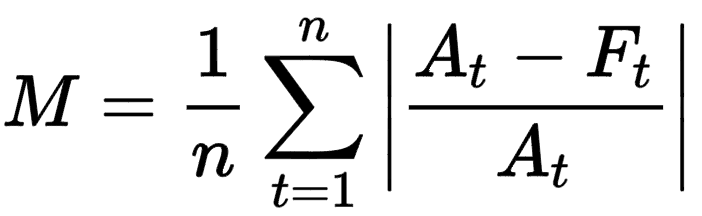
where M is the mean absolute percentage error, At is the actual value, and Ft is the forecast value.
MAPE is a common metric for evaluating models in regression problems, providing an intuitive measure for measuring accuracy.
Symmetric Mean Absolute Percentage Error (SMAPE)
SMAPE is calculated by:
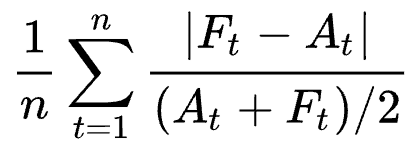
SMAPE normalizes for the scale of the labels and also for the scale of the predictions. Similar to RMSE, this is especially useful if a label is 0 or near 0.
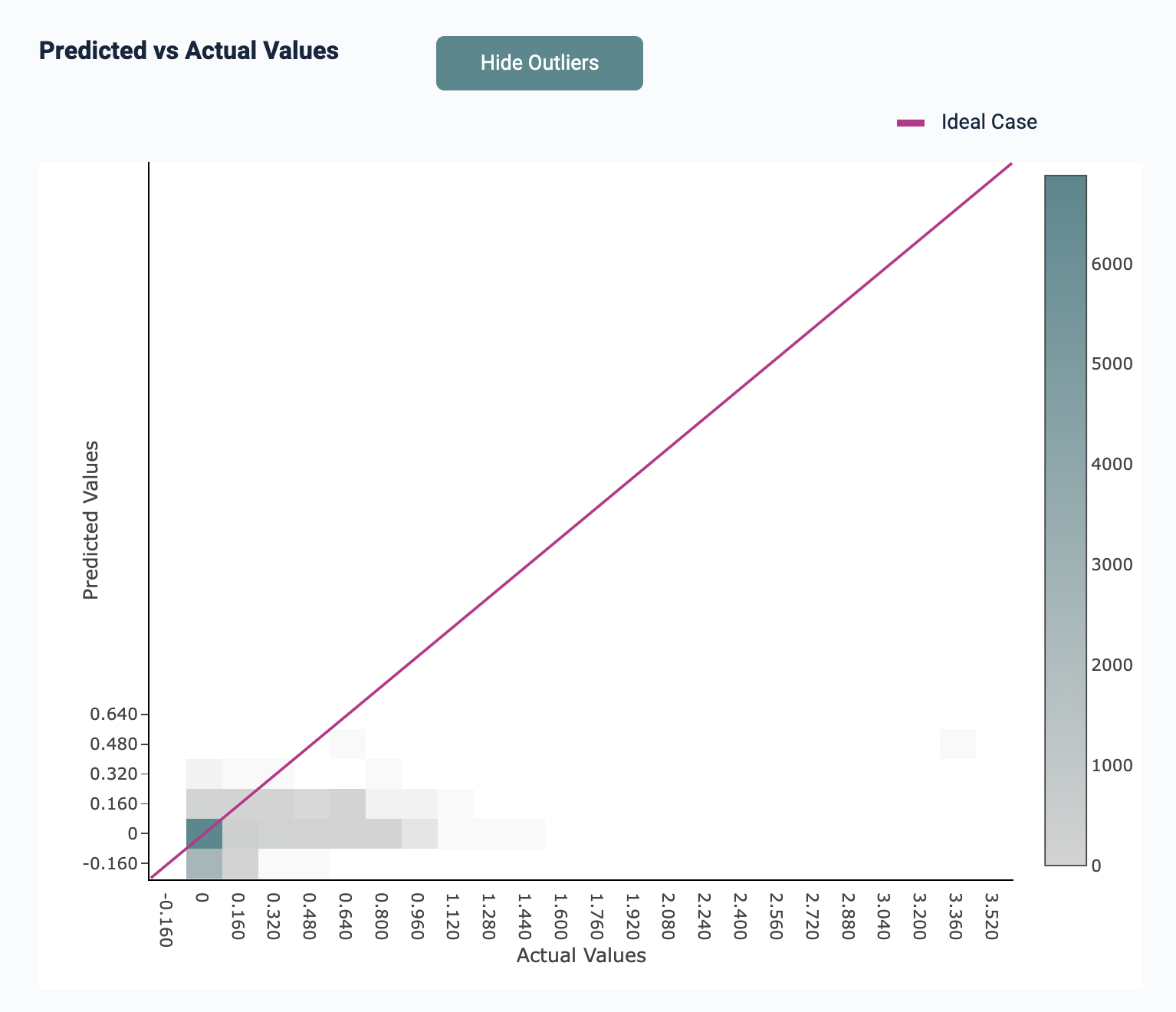
Heatmap of Predicted vs. Actual Values
Kumo provides a heatmap of predicted values versus the actual target labels for all entities in the predictive query, in your training table's holdout and evaluation set. This can be used to spot-check the quality of your trained predictive query. The predictions are generated by applying the trained predictive query to every single row in the training table that was generated during predictive query training. The actuals are the target labels from the training table.
Distribution of Predictions Histogram
Kumo also provides a histogram of the predicted values alongside the actual target labels for all entities in the predictive query, in the holdout and evaluation set of the training table. This can be used to spot-check the quality of your trained predictive query. The predictions are generated by applying the trained predictive query to every single row in the training table that was generated during predictive query training. The actuals are the target labels from the training table.
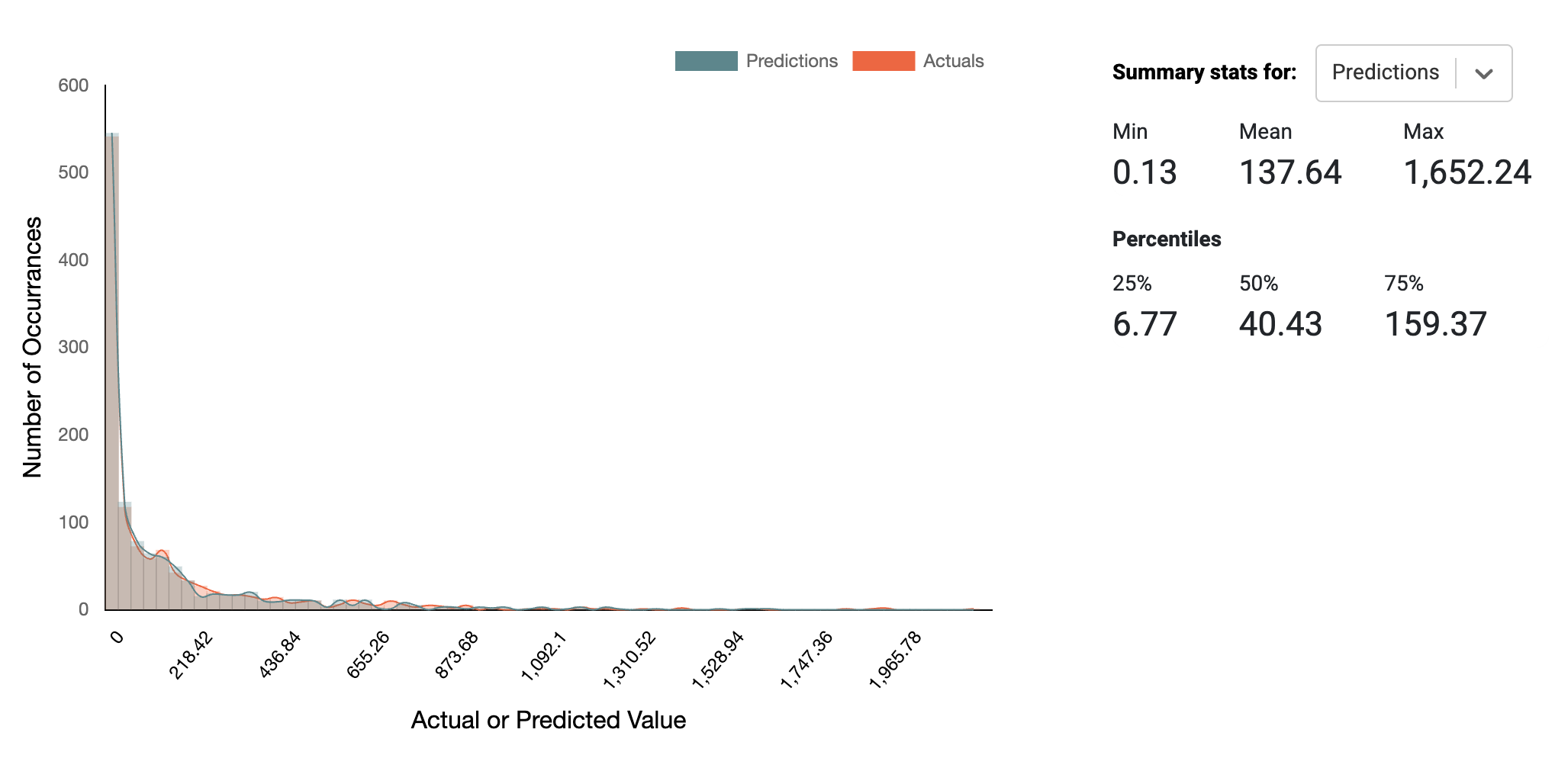
Ideally, the shape of the two distributions should match; however, some divergence should be expected in normal cases, even for well-written predictive queries.
Updated 3 months ago