Shipment Delay Prediction
Solution Background and Business Value
Shipment delays can significantly disrupt the supply chain, leading to increased operational costs and inventory shortages. These delays can cause a ripple effect, impacting production schedules, customer satisfaction, and overall business efficiency, ultimately affecting a company's bottom line and competitive standing in the market.
This solution covers shipment delay prediction using Kumo that involves leveraging historical data about the shipments delivered in the past to predict potential delays in delivery schedules. You can build a model using data about past shipment records, carrier performance, and external factors that impact transit times to make accurate predictions, without having to invest time in carefully preparing the features across all signal sources.
Delay prediction models can be used in downstream decision-making to surface/mitigate risks and optimize logistics operations. By using these models to enable better planning and resource allocation, reduce costs associated with last-minute adjustments, and improve overall supply chain efficiency, organizations in turn provide more reliable service, foster customer loyalty, and bolster competitive advantage in the marketplace.
The solution discussed here is an example from the e-commerce delivery service but this structure can be adapted to predict shipment delays for other industries with a few adjustments
Data Requirements and Kumo graph
The problem can be tackled with a minimal set of tables, but we will also provide some examples of tables which can also be included to improve the model. In general, any type of data can be included if you deem it to hold useful signals.
Here is an example of what the Kumo graph could look like for late shipment prediction:
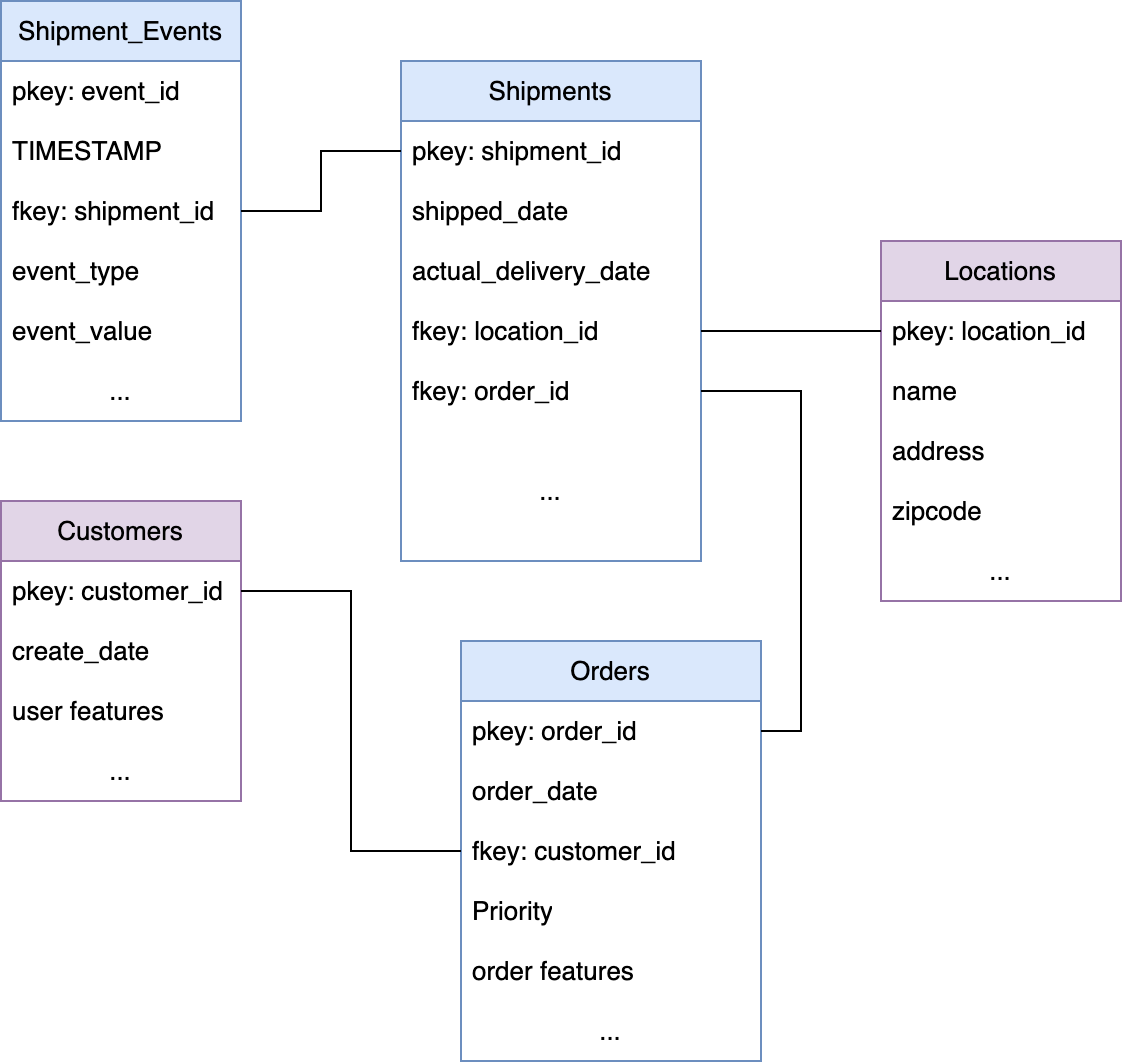
Core Tables
- Shipments: This table contains the basic information about each shipment.
- shipment_id (Primary Key)
- order_id (Foreign Key referencing Orders)
- origin (Origin location)
- destination (Destination location)
- ship_date (Date the shipment was sent)
- actual_delivery_date (Actual delivery date): Can be separated into an additional table to make sure that the model doesn't use it to avoid leakage.
- Orders: This table holds information about customer orders that correspond to shipments.
- order_id (Primary Key)
- customer_id (Foreign Key referencing Customers)
- order_date (Date the order was placed)
- total_amount (Total amount of the order)
- priority (Order priority: High, Medium, Low)
- Customers: This table stores information about the customers placing the orders.
- customer_id (Primary Key)
- customer attributes
- Locations: This table details information about various locations (warehouses, delivery points).
- location_id (Primary Key)
- location_name
- address
- city
- state
- zip_code
- Shipment_Events: This table logs events related to each shipment’s progress, including possible delays.
- event_id (Primary Key)
- shipment_id (Foreign Key referencing Shipments)
- event_date (Date and time of the event)
- event_type (Type of event: Picked up, In transit, Out for delivery, Delivered, Delayed, etc.): Type of event will be crucial for us to define the necessary labels
- event_value (Value for each specific event), for delayed events it can be the
delay_duration - location_id (Foreign Key referencing Locations)
Additional Table Suggestions
You can also supplement above core tables with additional tables:
- (optional) Carriers: This table includes information about the carriers handling the shipments.
- carrier_id (Primary Key)
- carrier_name
- contact_info
- (optional) Weather: This table records weather conditions that could affect shipment delivery.
- weather_id (Primary Key)
- timestamp (Date of the weather record)
- location_id (Foreign Key referencing Locations)
- weather_condition (Description of the weather: Sunny, Rainy, Snowy, etc.)
- temperature
- wind_speed
- (optional) Traffic: This table contains traffic condition data.
- traffic_id (Primary Key)
- date (Date of the traffic record)
- location_id (Foreign Key referencing Locations)
- traffic_condition (Description of traffic: Light, Moderate, Heavy, etc.)
- (optional) Delays: This table logs known delay causes and their details, can be joined with Shipment_Events to define more complex queries
- delay_id (Primary Key)
- shipment_id (Foreign Key referencing Shipments)
- delay_duration (Duration of the delay in hours or days)
- delay_reason (Reason for delay: Weather, Traffic, Mechanical issue, etc.)
Predictive query
Using the same Kumo graph we created above, multiple PQueries can be written to address the business question that logistics managers might want to address:
Predict if shipment will be delayed:
This is a static PQ, which requires a static label - we can easily achieve by including delayed and delay_duration columns in the Shipment's table (join with Shipment_events)
PREDICT Shipments.delay_duration > 0
FOR EACH Shipments.shipment_idPredict if the shipment will be delayed delay only for shipments that were shipped within last 7 days:
PREDICT Shipments.delay_duration > 0
FOR EACH Shipment.shipment_id
WHERE COUNT(Shipment_events.event_type,-7,0,days) > 0Predict if the shipment will be delayed after the shipment has reached its first location:
PREDICT COUNT(Shipments.event_type == "Delayed", 0, X) > 0
FOR EACH Shipment.shipment_id
WHERE COUNT(Shipment_events.event_type == "Shipped" ,-7,0,days) > 0
AND COUNT(Location.location_id, -7,0, days) == 2Predict the delay duration for all shipments:
Instead of predicting binary labels, we can regress on the delay_duration and predict how much each shipment will be delayed.
PREDICT Shipments.delay_duration
FOR EACH Shipment.shipment_idDeployment
Once you are comfortable with how well your predictive query performs using your historic data, you can easily productionize your model by setting up a new batch prediction workflow for any trained predictive query. Kumo can generate predictions or embeddings as batch prediction outputs, depending on whether you intend to directly use your model's output for making business decisions or as inputs for your downstream ML pipeline. In the latter case, Kumo can generate batch predictions and write them to your preferred destination (e.g., Snowflake/Databricks/Google BigQuery data warehouse or S3 bucket). The output can then be consumed directly by analysts or connected to a downstream application for stakeholders to consume and put it into action.
Updated 2 months ago