Related Products
Solution Background and Business Value
This solution is concerned with recommending similar items, also called item-to-item recommendation, as we are recommending similar items for a specific item. A common e-commerce use case involves finding products that are most similar to items what the customer is interested in. This could be items that are currently being browsed by the customer, or items that are most similar to something they just purchased. Item-to-item recommendation models are at the core of “You might like this because you bought/viewed/clicked on this” personalization solutions, which are everywhere in e-commerce!
Kumo can help you create rich item embeddings that are tuned for which products are likely to be purchased together. Kumo can capture rich item similarity, not simply just just variants of the same product (e.g., 1% versus 2% milk), but instead based on different items co-purchased (e.g., milk and cereal). Moreover, the training can be balanced with other cooccurrence signals, like views, basket events, or reviews.
We’ve observed on real data that graph embeddings trained this way outperform semantic embeddings using LLMs when trying to predict similar items via co-purchase events; furthermore, the basic approach outlined in this solution can be supplemented with LLM/word embeddings using Kumo!
Data requirements and Kumo graph
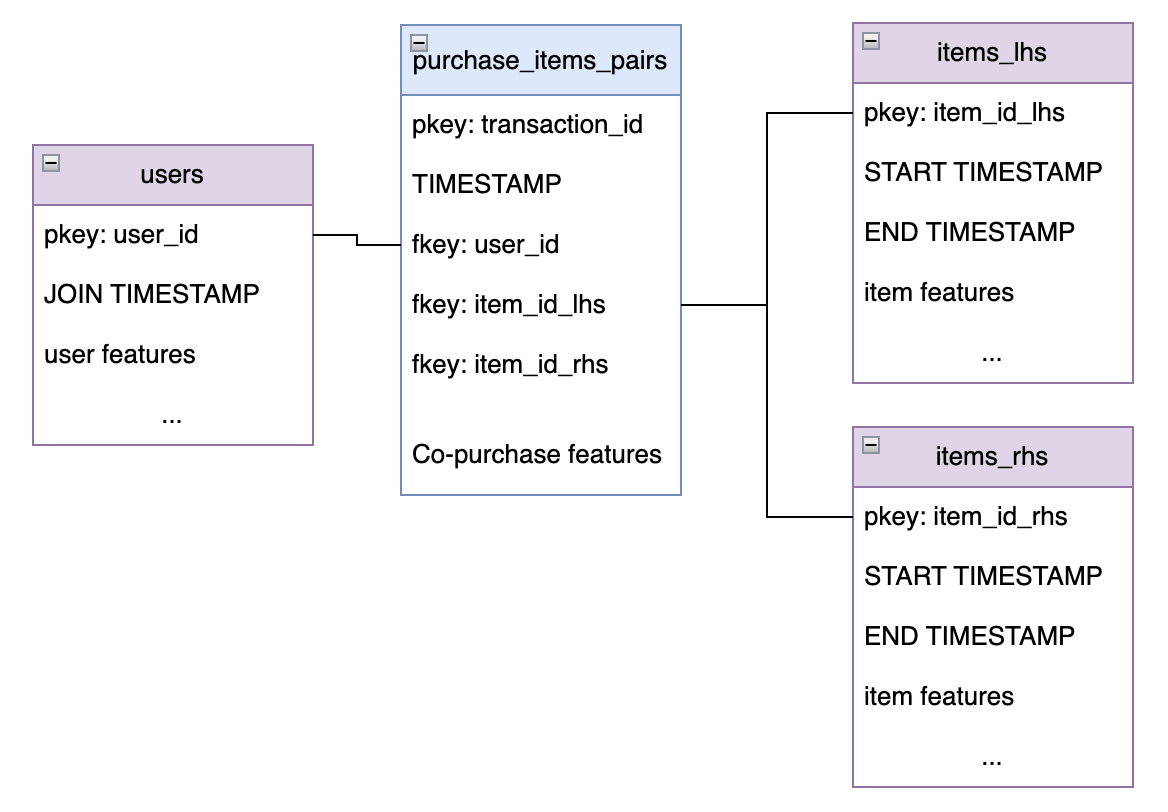
Core Tables
The solution requires a minimum set of table in order to define the necessary labels and relevant entities. At the core of the solution lies the Purchase item pairs table which is used as the item similarity label.
- Purchase item pairs table: defines the item co-occurrence events, and it is up to the business to decide what notion of co-occurrence to use, one of the advantages of Kumo is that different tables can be easily substituted and models can be trained/evaluated quickly to facilitate the necessary experimentation here. For example: we can define the rows in this table as “products purchased by the same user with in 7 days”, or “all products purchased by the same user within a single web-session”. Your specific business context will dictate this, but a good rule of thumb is average number of days between customer purchases.
- It should be noted that this table likely needs to be created from
userandtransactiondata as purchase pairs are typically not stored as part of a typical data schema.
- It should be noted that this table likely needs to be created from
- The next two tables you will need are unique items tables. Because our primary table is pairs of items, we also need each item to be represented in a unique item tables. In the diagram below we label these unique item tables with the suffix
_lhsand_rhs(left/right hand side). It is important to note that even if the left-hand and right-hand side items are the same, both tables need to be loaded into Kumo separately. The data in the item tables might be the same, but Kumo needs both sides of the item pairs to properly train embeddings. - Finally, you will likely want to include a users table that has information on customers who are making the purchases.
Suggested additional tables & data
- (optional) Product category data —this would help the item embeddings account for similarity of products in the same category (shirts versus shoes).
- (optional) Web browsing data—you could also include time-stamped browsing events for users. This could help inform which products are more relevant.
- (optional) Add image and item description columns into the
items_rhsanditems_lhstables.
Predictive Query
The predictive query below is fairly simple. It just predicts all item_ids (right hand side) for every input item_id (left-hand side). This approach is using Kumo in a static setting, which simply means it’s not creating a moving time-window during training.
PREDICT LIST_DISTINCT(purchase_item_pairs.item_id_rhs)
RANK TOP 20
FOR EACH items_lhs.itemd_id_lhsIf you want to create time-based version of this model where it ranks items across time, you can simply include:
PREDICT LIST_DISTINCT(purchase_item_pairs.item_id_rhs, 0, N, days)
RANK TOP 20
FOR EACH items_lhs.itemd_id_lhsAdditional considerations during modeling:
In situations where products are constantly changing and you have a lot of “cold-start” items at prediction time, you may want to consider a specific option in model planner. The below change tells Kumo to build samples that will account for a majority of cold-start items.
handle_new_target_entities: trueDeployment
It is common at prediction time to want to treat the LHS and RHS differently. For example, the LHS might be all items in the product catalog, but RHS might be only recently added items. In Kumo you have the option to create predictions/embeddings for all items at every run, you can filter the RHS items to only recommend new items, you can filter LHS items to only recommend similar items for new items, or a combination of both—depending on the requirements of your use case.
Using Kumo Predictions in a Key-value Store
The deployment mode depends on the latency requirements of the downstream applications. One common product built on item-to-item recommendation of this kind is augmenting the checkout process on e-commerce sites. At the point of checkout we want to recommend “commonly bought together items” in a carousel below the basket contents. We can build this solution using Kumo predictions in a batched fashion, where we produce item-to-item recommendations for each item in the catalogue and store the predictions in a key value store:
ITEM_ID_1 : {ITEM_ID_A, ITEM_ID_G, ..., ITEM_ID_N} # LHS_ITEM : {Recommended items for LHS_ITEM}At serving time we can retrieve the RHS items and serve them in the carousel at checkout.
Creating Similarity Scores via Dot Products
Kumo batch prediction will create predictions or embeddings, we already described how to use predictions and a key-value store to serve a carousel product at checkout. But for applications where a small number of RHS recommendations is not sufficient we can use the embeddings directly. You can calculate the dot product between LHS and RHS embeddings to produce a similarity score outside of Kumo. This approach can be used to power applications with strict filtering and/or latency requirements.
One example might be “you might also like” carousel for un-authenticated users browsing our item catalogue. We want to show items which are often browsed/bought together based on the session so far, but we want to omit any items that have already been viewed as part of this session. We can use Kumo predictions and embeddings in tandem to solve this problem:
- Cache top-10 recommendations for each item in a low latency key-value store
- Store LHS embeddings and RHS embeddings in a vector database
- As the user continues their session:
- Show items they might also like based on Kumo predictions (similarity scores) for items they have viewed so far or have in their basket.
- As the user exhausts the
ITEM_IDsin the cached predictions backfill the carousel using the dot product similarity score on the fly.
Updated 3 months ago