Uncovering Credit Card Fraud
Solution Background and Business Value
Credit card fraud is a prevalent issue that affects financial institutions, businesses, and consumers globally. The fraud occurs when a fraudster gains unauthorized access to a customer’s credit card information and subsequently makes unauthorized transactions. This type of fraud can happen in various forms, such as physical theft of the card, skimming of card details, or through online breaches where card data is stolen and used for fraudulent purchases or cash withdrawals.
Implementing machine learning models to detect signs of credit card fraud that can be integrated into companies’ fraud detection systems will help them identify potentially fraudulent activities in real-time. This proactive approach allows for immediate intervention, reducing the incidence of fraud and minimizing financial losses for both the institutions and their clients.
Data Requirements and Kumo Graph
Kumo GNNs can work with any dataset in a relational form, that is a collection of tables interconnected with primary and foreign key relationships. While it is possible to build a Kumo model with just a single table, we recommend starting with at least a few core tables which include the most important signals for a particular task. Our models leverage complex relationships between entities in the graph, along with their features to make accurate predictions, therefore we can use tables in their raw form and no feature engineering is necessary.
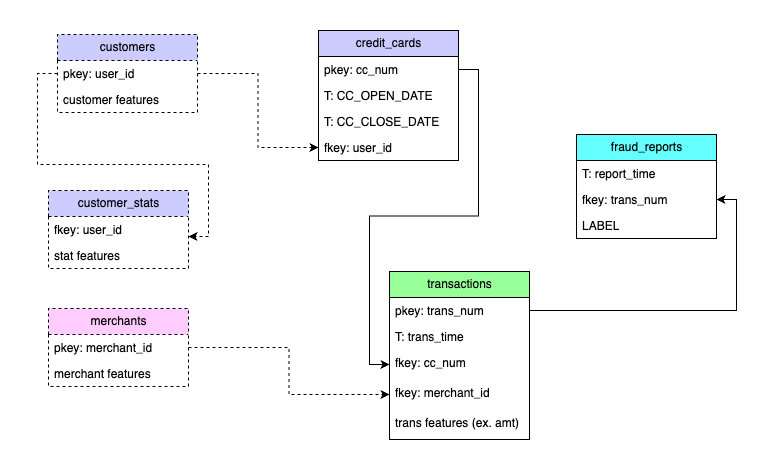
One example of a graph you might use for credit card fraud detection. The dashed lines signify optional tables and connections.
One example of a graph you might use for credit card fraud detection. The dashed lines signify optional tables and connections.
Core Tables
At minimum we recommend starting with tables that include all the relevant entities and facts for the task at hand. For the case of credit card fraud, we can have several entities for example credit card entities, user entities, merchant entities. The relevant events we might record in this use case are credit card transactions and fraud reports. We can extend the graph with other sources of signal, like merchant entities or credit report events for example.
- Transactions: Transactions are at the core of credit card fraud detection. Most commonly the label appears at a transaction level, e.g. this transaction is either fraudulent or not. The transactions table should include all the relevant recorder transactions, that is all the transactions made using the credit credit cards of our customers. Each transaction should include a unique identifier
transaction_idthat can be used to connect to other tables, namely the fraud reports table (see below). Additionally, every transaction has aTIMESTAMPwhich records the point in time when the transaction occurred and allows us to treat the problem in a temporal way (see following section). The transactions table should also include other foreign keys, which connect to relevant tables, e.g.credit_card_idto connect to the credit_cards table, andmerchant_idto connect to the merchants table if available. The table can also include any attributes we can assign to the transactions themselves, for example the location, currency, amount, etc. - Credit Cards: Credit cards are the entities which allow us to connect and learn across many transactions. The credit cards table should include a unique
credit_card_id, and can optionally include two timestamp columns: one recording when the credit card was open and another to record the timestamp of the credit card being closed (can be left empty or excluded if this information is not available), e.g.CC_OPEN_DATEandCC_CLOSE_DATE. The table can include any other attributes we can assign to a specific card, e.g. limit, APR, etc. - Fraud Reports: The fraud reports table records all labels about transactions we have collected. It must contain a foreign key column
transaction_idwhich links to the specific transaction that was labelled, it must also include aLABELsignifying if the transaction is fraudulent or not. This table should also include aTIMESTAMPcolumn. Depending on what type of ML model we intend to use the fraud reports table can be joined into the transactions table in which case this table doesn't need to appear in the Kumo graph.
Additional Table Suggestions
If we have additional data available we can easily extend the above core tables by including additional tables in the graph. Here are some suggestions of which tables we can also use:
- (optional) Users: The customers table holds information about the credit card users. The table should include a unique identifier for each customer, e.g.
user_id. We can extend the graph with this table by including theuser_idas a foreign key in the table of credit cards. With this extension the models can learn to reason across users with many credit cards. The table may include other customer features such as, age, location, etc. - (optional) User stats: Stats (e.g. number of transactions in the last 30 days, volume in $ of transactions in the last 30 days, credit score, etc.) associate with each user and the
TIMESTAMPof their measurement. - (optional) Merchants: The merchants table holds information about the merchants/vendors that participate in each transaction. The table should include a unique
merchant_idprimary key, which connects it to other tables in the graph. To extend the graph with this table thetransactionstable should includemerchant_idas a foreign key. The table may also include other account features, like category, location, , etc.
Predictive Query
We can approach detecting credit card fraud from many aspects. The most natural is at the transaction level, where the model predicts if a given transaction is fraudulent or not based on the provided labels in the transaction table (for this to work we need to join the fraud_reports table with the transactions table so that the label column is available):
PREDICT transactions.LABEL
FOR EACH transactions.transaction_idWhen making predictions for new transactions, we can just leave the LABEL column empty, and then run batch predictions. This approach works well if we want to build an automated system to classify fraud at the transaction level as it occurs.
We can also reframe the problem in a temporal manner, e.g. will a fraudulent fraud report be associated with a transaction in the following 30 days:
PREDICT SUM(fraud_reports.LABEL, 0, 30, days) > 0
FOR EACH transactions.transaction_id
ASSUMING COUNT(fraud_reports.*, 0, 30 days) >= 1The predictive query language (PQL) is very flexible and allows us to easily define temporal queries, where the target is an aggregation of events over a future time range. This allows us to create models which make predictions for entities different from transactions (e.g. credit cards). For example we can predict if a fraudulent transaction will be associated with a particular credit card in the next 7 days.
PREDICT COUNT(transactions.LABEL, 0, 7, days) >= 1
FOR EACH credit_cards.credit_card_id
ASSUMING COUNT(transactions.LABEL, 0, 7, days) >= 1Deployment
The deployment of machine learning models for credit card fraud detection is intricately linked to the sophistication of the underlying fraud detection infrastructure. Credit card fraud involves complex, imbalanced binary classification challenges, where labeling data accurately can be both labor-intensive and costly. Models capable of generating reliable predictions with minimal labeled data can significantly reduce operational expenses. Leveraging Kumo models, which utilize both individual entity features and contextual relational data, enables effective early-stage predictions with fewer examples.
Due to the dynamic nature of credit card fraud, with fraudsters constantly evolving their tactics, it is essential to employ a hybrid approach that combines machine learning with human oversight.
Initially, with limited labeled data, machine learning models can guide the efforts of fraud teams by highlighting suspicious transactions. For credit card fraud, this involves generating batch predictions for transactions deemed high-risk. These predictions can then inform a scoring strategy that prioritizes transactions for review and labeling, enhancing the efficiency of human analysts. This process accelerates the progression to a more automated stage of fraud prevention.
As the system matures and accumulates a sufficient volume of accurately labeled data, the models become adept enough for more autonomous operation, aiming to preemptively block fraudulent transactions. At this advanced stage, the role of the human fraud team evolves towards system maintenance and the identification and labeling of new fraud patterns, particularly those represented by model-generated false negatives. This continuous cycle of human and machine collaboration ensures the system remains robust against the evolving landscape of credit card fraud.
Updated 3 months ago