Churn Prediction
Solution Background and Business Value
Customer churn predictions are a powerful tool to optimize the growth funnel. By identifying users that are likely to churn (eg. unsubscribe, stop purchasing, etc), business can take proactive action to retain them, such as sending personalized notifications, or even discounts/coupons.
In this solution, you will learn how to use Kumo to:
- Train a churn model, custom-tailored to your data schema and business space
- Use the Kumo REST API to export predictions to your CRM platform on regular basis
- Send personalized call-to-actions via email/text/push notification to customers that are most likely to churn.
Kumo’s Predictive Query language is highly flexible, enabling teams to experiment with many different definitions of Churn, to learn what works best for the business. Here are some examples of different churn definitions that Kumo can support:
- Predict folks who are likely to cancel their subscription within the next 3 months
- Predict folks who are unlikely to log in the next 7 days
- Predict folks who are unlikely to make a purchase in the next 30 days
Data Requirements and Kumo Graph
Core tables
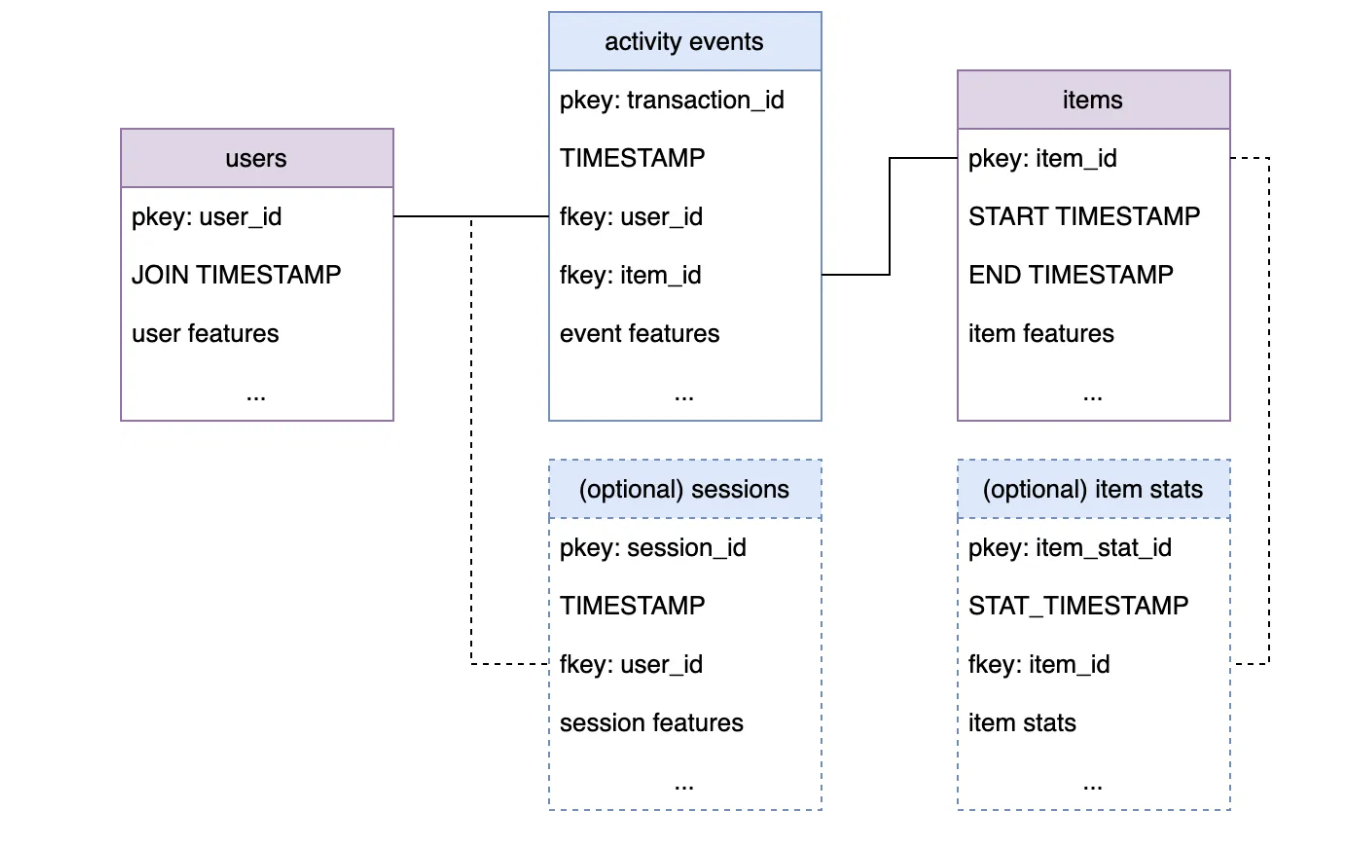
Regardless of approach taken, a core set of tables will be needed to tackle this use case. Below is an non-exhaustive list of what data needs to be included:
- Events: the events table holds information which signifies user activity. For example the events table can hold transactions in a market place, subscription/re-subscription events, stream events, or whatever event signifies user activity. This table should include information associated with this particular event/transaction/order, must have a
timestampanduser_idas the foreign key so each event can be linked to a particular user. - Users: The users table should include information about users, these are the entities we want to make predictions for. It must include a
user_idprimary key that can be linked to that user’s activity events in the events table. - Items: The items table should include static data about items that users can interact with (items for purchase, movies that can be streamed etc.). The table must include an
item_idprimary key that can be linked to an event.
Additional Table Suggestions
We can supplement the above core set of tables with many other data, depending on the application:
- (optional) Merchants: Static information about merchants in the marketplace
- (optional) Merchant/Items statistics: Regularly updated statistics about merchants/items. Particularly useful in scenarios with few events.
- (optional) Sessions: data about a user’s sessions
- (optional) Clicks: clickstream data about a user’s interaction with certain items. May be similar to session data.
- (optional) Reviews: User reviews of items
- (optional) Comments: User comments associated with each event/item
Each of the above tables can be incorporated into the graph via suitable pkey to fkey relationship.
Predictive Query
The exact predictive query depends on how we define user churn. If, for example, we define a churned user as a user who does not make a purchase in the next X days given that they have made a purchase in the last Y days, we can train a model to predict this behavior as:
PREDICT COUNT(orders.*, 0, X, days) = 0
FOR EACH users.user_id
WHERE COUNT(orders.*, -Y, 0, days) > 0If, for example, we define a churned user as a user who does not stream anything in the next X days given that they have had active sessions in the last Y days, we can train a model to predict this behavior as:
PREDICT COUNT(streams.*, 0, X, days) = 0
FOR EACH users.user_id
WHERE COUNT(sessions.*, -Y, 0, days) > 0Finally, if we want to model churn as explicit unsubscription events from our service for users who are currently subscribed and we have a suitably defined user-event table, we can train the model as:
PREDICT COUNT(user_events.unsubscibed == True, 0, X, days) > 0
FOR EACH users.user_id
WHERE LAST(user_status.subscribed, 0, -Y, days) == TrueDeployment
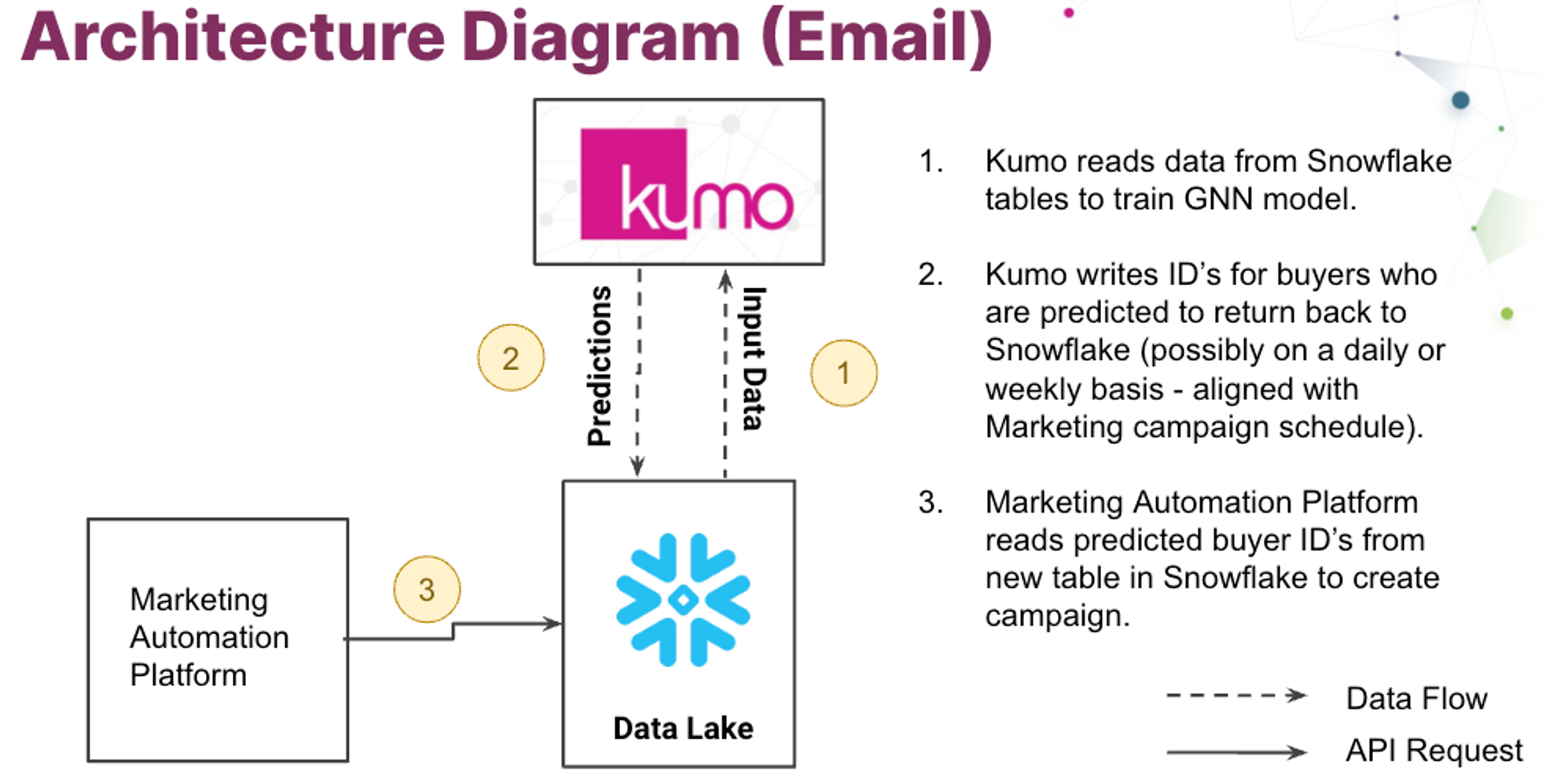
Churn predictions models are often a necessary first step towards building an automated growth machine learning strategy. One of the simplest ways to deploy churn models is to:
- Use Kumo to predict churn probability.
- Write a SQL view on the predictions, to identify a subset of user IDs which should receive an email.
- Export these user IDs to a cross-channel marketing orchestration platform, such as Braze or Marketo.
- Send a personalized email to these users, to help them re-engage.
- Orchestrate all of the above steps to happen automatically, such as on a weekly basis, using your existing orchestration tool such as Airflow or Dagster.
Future Improvements
In practice, we see customers get the most value by combing churn models with other models, such as Personalization or LTV models. This lets teams drive more efficiency from their promotional campaigns, such as:
- Using a Churn + LTV model, teams can send emails to “high value users that are likely to churn”. After all, there is little value in spending promotional budget on users that will have low lifetime value.
- Using a Churn + Personalization model, teams can send personalized product promotions to users that are likely to churn. In practice, a highly quality recommendation is one of the most effective ways to get a customer to re-engage.
Updated about 2 months ago