How are Kumo table columns preprocessed?
Learn how Kumo preprocesses different column types for accelerating pipeline development.
Kumo automatically detects the column types in the ingested tables, but you can also change the auto-assigned column type based on your domain-specific knowledge.
You can set your column types during the Preprocessing stage of the Kumo table creation process.
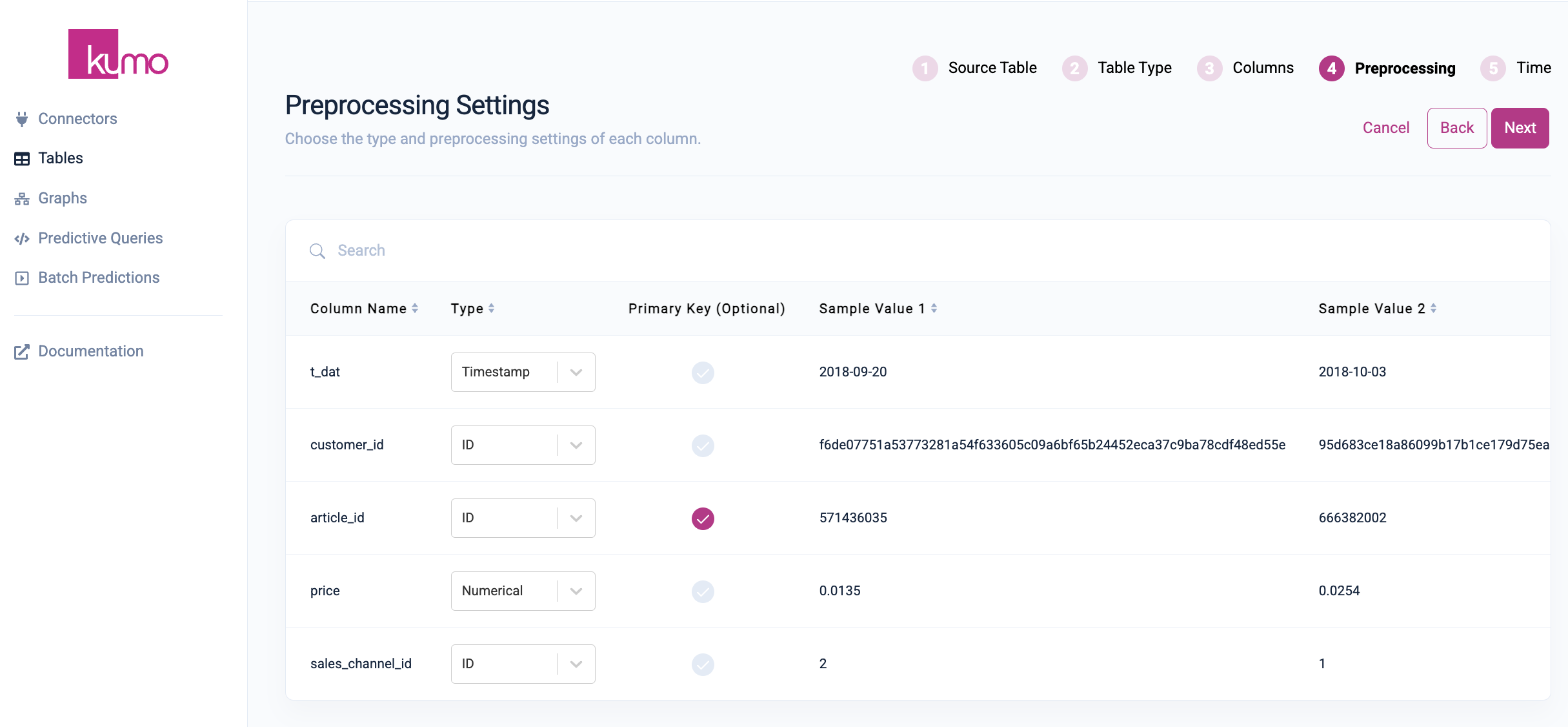
The following sections elaborate on the various types of preprocessing Kumo applies to your ingested data based on the selected column type.
Numerical Data
Numerical data contains numbers that are integers, floats, or other numerical data types in column values. Typically, Kumo preprocesses numerical data by standard normalization. However, edge cases may exist where Kumo doesn't apply standard normalization. For example, if the data is heavily skewed towards the maximum or minimum end of the distributions, Kumo will apply variants of the logarithmic function so that the end result is a less skewed normalized distribution.
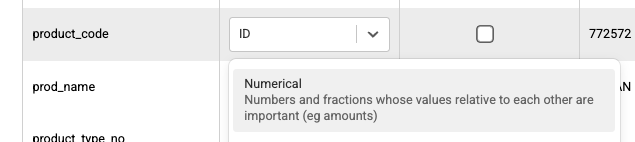
Another kind of edge case is when data is stored as integer values, but the information is categorical in nature. For example, you might have a column for product type, where each type is one of types 1, 2 and 3. Kumo will preprocess these integer values the same way as categorical data—no numerical normalization. If the number of unique values in an integer type column is less than a threshold of 4000, Kumo marks this column as a categorical type column by default.
Missing values in numerical data are filled with the mean value of the valid entries in the same column.
Categorical Data
Categorical data may be represented by booleans, strings, and integers. Kumo provides the option to encode categorical data into one hot vectors or map categories to indices each representing a different category.
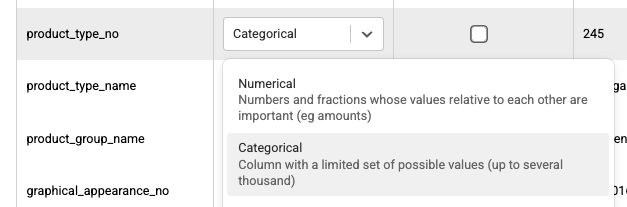
One-hot encoding applies to boolean columns and string or integer columns with less than 10 unique values (the default maximum allowable number of one-hot categories). For columns with many unique values, Kumo maps each category to an integer value, creating a 1-1 shallow embedding for the categories.
A missing value in categorical data can sometimes be considered useful information. By default, such data points are categorized into a "N/A" category with its own embedding.
Multi-categorical data
Sometimes one column may contain string data that is the concatenation of multiple categories. For example, in a dimension table with article id as the primary key, one column might contain entries formatted as {category 1},{category 2},{category 3} or {category 1} where each entry contains all categories this data point belongs to, separated by a comma. Kumo calls such columns multi-categorical columns and converts them to a multi-hot encoding representation. A multi-hot encoding creates one column for each unique category in the original data column, and the new column will be filled with a value of 1 if the category is true.

Missing values in multi-categorical type columns are categorized into a “N/A” category with its own embedding.
ID Data
ID data contains information that uniquely identifies an entity or a group. ID type columns generally contain a large percentage of unique values.

The first step we take in preprocessing ID data is checking the number of unique value, and proceed based on the case it falls under:
- Total number of unique values is no more than 4000: Kumo treats this ID column as categorical data.
- Number of unique values is greater than 4000 but no more than 80% of the total number of samples: convert the ID string into a MD5 hash of the string.
- Otherwise: drop this column. This ID column contains little information on how data points are grouped together.
Missing values in ID type columns are categorized into a “N/A” category with its own embedding.
Timestamp Data
Temporal data contains date/time information. Kumo extracts the year, month, date, hour, minute, etc., when applicable.

A timestamp data entry is filled with the value 0 in the case of missing data.
Text data
Text data contains natural language or other types of text. Kumo first determines whether a piece of text is natural English text.

Current steps for determining whether a piece of text is English are as follows:
- Text should have a reasonable overlap with English vocabulary that text encoders support. A piece of text is assumed to not be English if more than 50% of its words do not appear in the internal list of common English words.
- Text should have a low fraction of non-letter words/tokens. This is to drop non-english text (e.g., JSON configurations) or non-natural text (e.g., address lists, phone books) that were not dropped by the first filter. Text is assumed to not be natural if it contains more than 30% words/tokens that do not consist solely of letters.
- Entries must, on average, contain at least 3 words/tokens with at least one entry exceeding twice the average number of words. This is to filter out one or two-word entries which usually turn out to be personal information such as names. If column entries contain fewer than 3 words on average the column is assumed to not contain natural English text.
If a column is detected to not be natural English text through the above conditions, it is not encoded. Words in text that is detected to be natural are mapped to vectors using GloVe and combined with a Bag of Words model. The vector obtained as a result of this operation is used as the embedding of the entire text cell.
Embeddings
Embeddings consist of lists of floats, all of equal length, and are typically the output of another AI model.

If you would like to provide your own embeddings, they must conform to the following:
- S3 CSV - String representation of an array of floats: either
0.1,0.2,0.3or[0.1,0.2,0.3] - Snowflake - array of floats in a single column
- S3 Parquet - list of floats in a single column
Learn More:
Updated 2 months ago