Search/Browse Reranking
Solution Background and Business Value
Most search engines in e-commerce sites rely on ranking functions to estimate the relevance of “documents” (e.g., product descriptions) to search queries submitted by their users. Traditionally, Okapi BM25 has been the most popular algorithm for such tasks. Recently, businesses have started to rely on large language models (LLMs) to calculate the semantic (cosine) distance between documents and queries.
Both of these functions rank results purely based on text or text semantics. However, they do not consider other important business information that could lead to better user experiences and more sales for the business. Optimized and personalized search results can use historical business data to ensure that the ranked results are the most likely to be purchased, beyond mere language similarities, and that they provide the most relevant personalized results for each specific user.
Data Requirements and Kumo Graph
We can begin developing our search model with a small set of core tables. Kumo allows us to extend the model by including additional sources of signal.
Core Tables
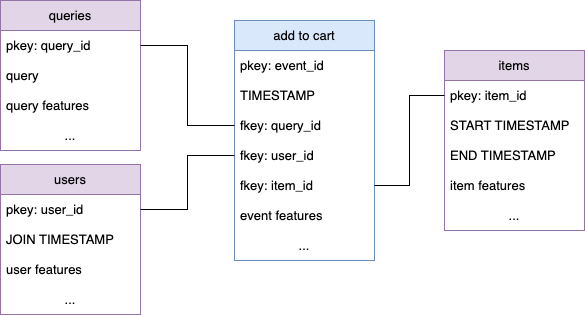
- Queries Table: This table holds information about all queries for which we want to make recommendations. It should include:
query_id: A unique identifier for each query.query: The unique text of the query.- Other attributes such as category or external LLM embeddings of the query.
- Items Table: This table contains information about the items available for recommendation. It should include:
item_id: A unique identifier for each item.START TIMESTAMPandEND TIMESTAMP: Columns to account for the availability period of items.- Other attributes such as description, color, category, and external LLM embeddings of the description and external vision embeddings of the product picture.
- Users Table: This table holds information about all users. It should include:
user_id: A unique identifier for each user.- Other features such as age, location, and
JOIN TIMESTAMP.
- Add to Cart Table: This table records all events from which the model learns to model query-item-user affinity. It should include:
TIMESTAMP: The time of the event.query_id,item_id, anduser_id: To link the event to specific queries, items, and users.- Other properties of the event.
Additional table suggestions
- Merchants Table: Information about merchants in the marketplace.
- Click Events: Records of which search results users clicked on.
- Item Rating Events: Numerical ratings of items by users.
- Item Return Events: Records of items returned by users.
- Comment/Review Events: Review data, including text.
- Wishlist Events: Records of items added to wish lists.
- And many more possibilities.
Predictive Query
In order to recommend the most likely items to be wanted given a query and to also personalize the ranking of those “relevant” items for each user, we need to train two models on the same graph. This approach ensures that we first identify the relevant items for a given query and then personalize these results based on the specific user's preferences.
Model 1: Query-Item Recommendations
This model recommends the top X items most relevant to a specific query by ranking items based on their historical affinity with similar queries.
PREDICT
LIST_DISTINCT(
add_to_cart.item_id, 0, N, days
) RANK TOP X
FOR EACH
queries.query_id
Model 2: User-Item Recommendations
This model personalizes the item recommendations by ranking the previously identified relevant items based on their affinity with the specific user's historical behavior.
PREDICT
LIST_DISTINCT(
add_to_cart.item_id, 0, N, days
) RANK TOP X
FOR EACH
users.user_id
Deployment
In production, we need to chain both models for any user query the system receives.
- Batch Predictions for Query Recommendations:
- Use the first model to produce batch predictions for the top X items recommended for all queries in the queries table.
- Refresh these predictions daily to capture any behavior changes in the data as new products emerge and buying trends change.
- Embeddings for Users and Items:
- Use the second model to produce embeddings representing users and items.
- Refresh these embeddings daily if possible.
Once these two datasets are created (the query recommendations from the first model and the user and item embeddings from the second model), load and cache them into your production system for use in real-time requests.
- Real-Time Query Handling:
- When a new query comes in, retrieve the item recommendations for that query.
- Rerank the results based on the dot product of those item embeddings with the user embedding from the user who submitted the query.
Elastic Search can be leveraged to load, cache, and retrieve these recommendations with low latency. It can also use efficient KNN search algorithms for embedding reranking.
Handling Non-Authenticated Users
If the user is not authenticated and there is no opportunity for personalization, the item recommendations for queries can be used independently. The recommendations from the first model come with scores that can be used for ranking.
Existing Search Engine Integration
If you wish to keep using your existing search engine retrieval algorithm (like Okapi BM25), you can still apply the second model to personalize the reranking of those results.
Updated 2 months ago