Model Tuning and Performance Guide
General Principles for Starting Out
Start Simple
Deep learning on graphs can be sensitive to noisy columns. When running experiments in Kumo, it might make sense to start with a minimal number tables and columns, then iteratively add features and check model performance for improved metrics. This approach has the added benefit of keeping the training pipeline fast, allowing for quick iterations.
Isolated Subgraphs
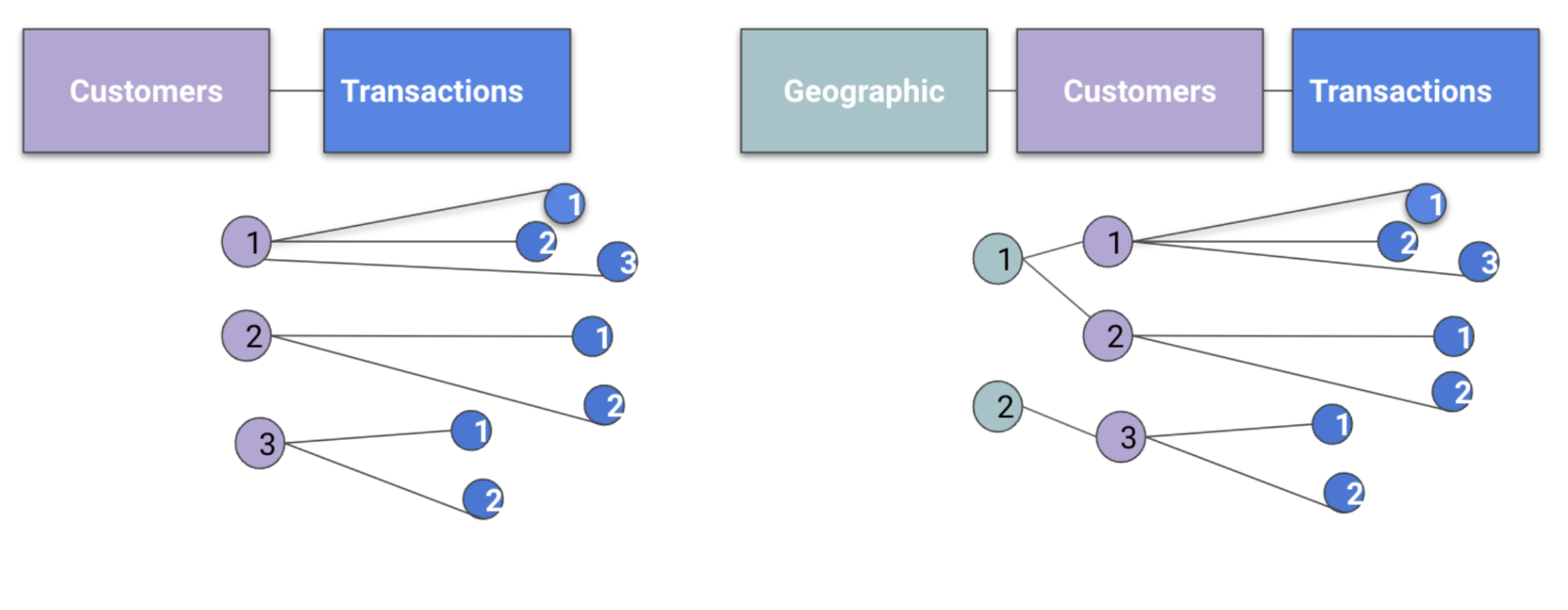
Another common issue is a data schema that does not allow entities to be connected. For example, you might have only two tables: a customer table as your entity, and a transaction table that is used to define the predictive target. In this example the customer (entity) only has a direct link to a transaction table. The graph will sample transaction information, but does not create features from “similar customers''. To do this, a third table that can connect across customers would be needed. Imagine a dimension table with static customer attributes like demographic or geographic information; now the graph has a way to sample features across similar customers that share traits (e.g. same zipcode).
In the following diagram, all three customers (purple) are initially disconnected. Including a geography table allows the graph to sample across customers (1 & 2)
Checking Loss Curves
During model training, Kumo will provide loss curves for every experiment. Similar to tensorboard, these loss curves help you check for underfitting or overfitting.
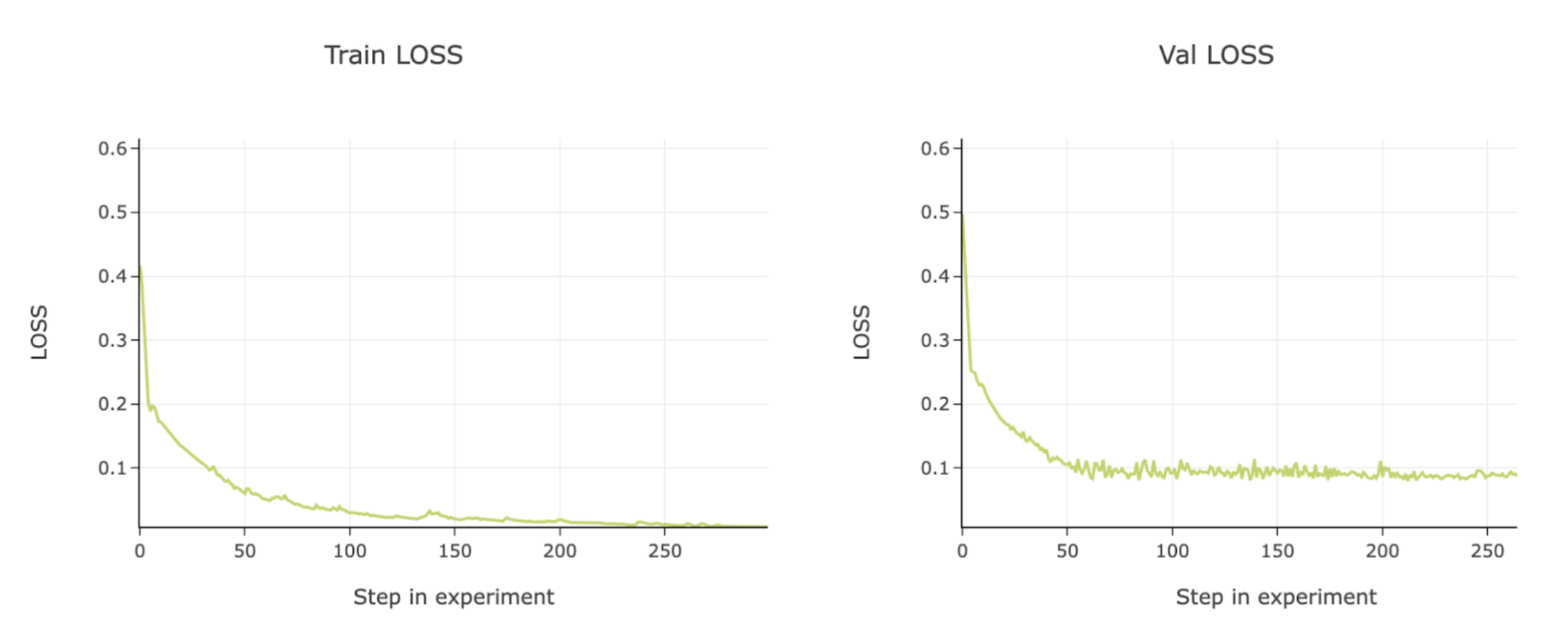
Signs of Overfitting
You see the validation set “level out” in the loss curve, but the training set will keep dropping. Additionally you will likely notice a big performance drop between training and validation metrics.
In the example below you can see the validation set levels out around epoch 50, but the training set keeps reducing loss to near 0.
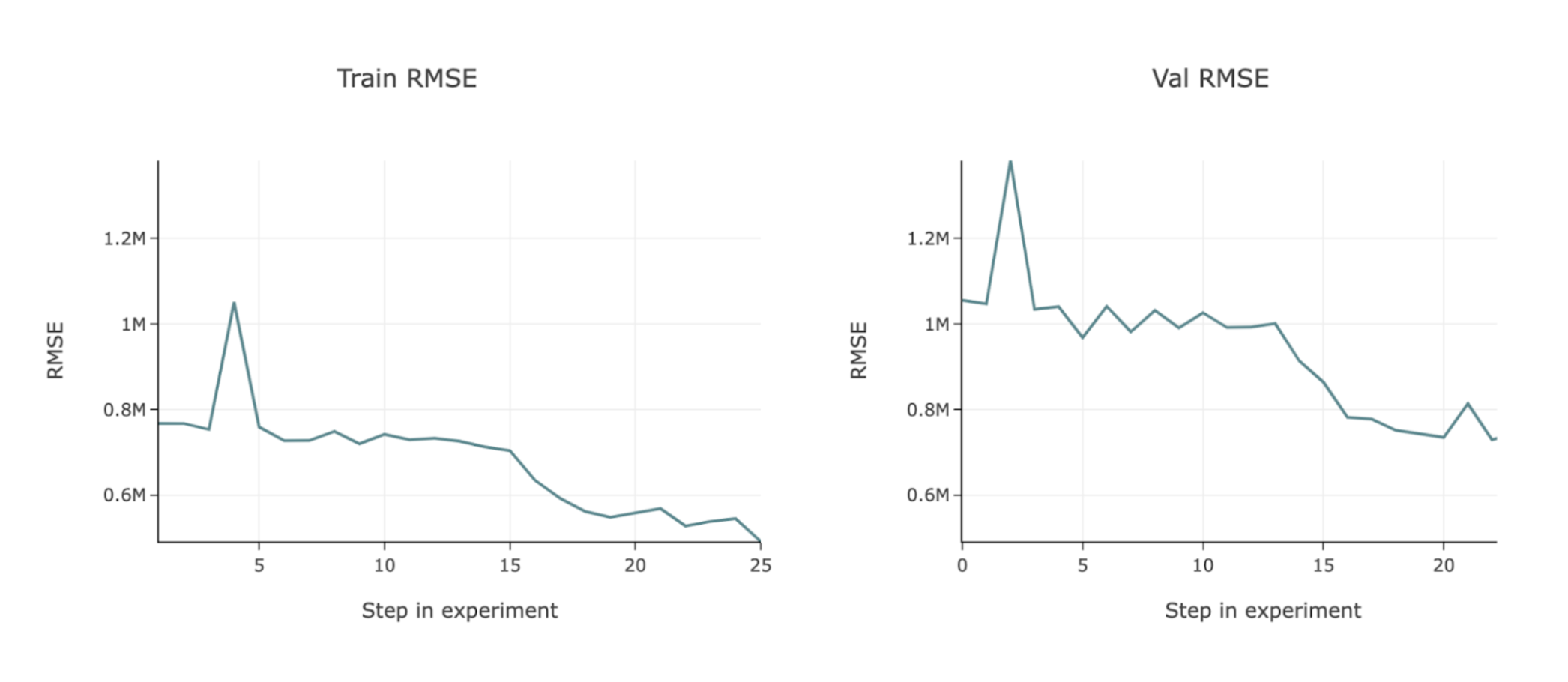
Signs of Underfitting
When underfitting happens, you will see loss (error) curves in the validation set that have not leveled out; this indicates that the training cycle ended before finding a minimal error for this model. Configuring the model planner to allow for longer training will help improve accuracy.
The following example charts RMSE loss—the validation set is still trending downward when the training is complete, indicating that it has likely stopped too early and could use more training time.
Check target leakage
Target leakage occurs when the input features of your model contain fields that allow "cheating" to occur. This generally results in high "simulated" performance on an offline holdout dataset, but poor performance when the model is actually deployed to production. The symptoms of target leakage are very similar to overfitting, but often more extreme.
To identify columns that are potentially leaking information, you can look at Kumo's explainability module. Explainability can tell you which columns are providing the most signal to the model, and you can use your intuition to determine whether these columns are leaking information.
Tactics For Improving Performance For Most Models
Increase experiments by setting num_experiments
num_experimentsYou can expand the parameter search space easily by increasing the number of experiments; this parameter is also set by run_mode.
- num_experiments The number of experiments for the AutoML trainer to run.
Allow the model to train longer
If loss curves do not converge, you can start by increasing the following model planner options:
- max_epochs : default value will depend on run mode (FAST -
12, NORMAL/BEST -16) - early_stopping : increase the patience value which is set to
3by default. This will allow the model to keep looking for decrease in loss before stopping the experiment. - max_steps_per_epoch : default value will depend on run mode (FAST -
1000, NORMAL/BEST -2000)
Increasing neighbor samples
If you have a large ratio between the number of entities and connections in the target table (in-degree), for example: customers have a high number of individual transactions, then you will want to increase the number of neighbors.
- num_neighbors : default value will depend on run mode (FAST -
12, NORMAL -16, BEST -23) - max_target_neighbors_per_entity : only used for temporal tasks
Expand the number of hops in your graphs
By default, Kumo uses two hops for traversing your graphs. This means that if a table is three hops away from the entity (or target), by default its rows will not be sampled. To fix this, increase the length of the num_neighbors list.
Change the validation and holdout samples
You can adjust the train/val/test splits to cover larger time periods. It may be that more validation data is needed during architecture search.
Change the tuning metric
Choosing the tuning metric can help you squeeze more performance out of a model. Kumo provides a large list of metrics that you can select the model to optimize for.
- tune_metric : choose the ML metric that you want to optimize the model for
Change the learning rate
Decreasing the learning rate could also improve performance when paired with longer training times. This also helps ensure that loss curves are stable and converge to a loss minimum. If loss curves are unstable, consider decreasing the base_lr.
- base_lr : This option provides a list of potential learning rates in model optimizer.
- lr_scheduler : A list of potential learning rate schedulers for model optimization.
Changing encoders
You may want to review that the most important signals in your dataset are being properly encoded into the neural network. Pay particularly close attention to text columns, as a variety of knobs exist for tuning the GloVe embedding generation.
- encoder_overrides : allows you to configure the way Kumo processes your input data and override the encoders that are inferred by Kumo.
Refitting on more data
Describe using this to help with performance changes between validation and holdout metrics.
- Refit_full: takes the best AutoML configuration and re-trains on the full dataset.
- Refit_trainval: specifies whether to refit the model to new training values.
Tactics to Improve Performance on Link Prediction
Embedding vs. Ranking
For temporal link prediction tasks, you can instruct Kumo to focus on either creating good ranking predictions, or good embeddings.
If you plan to use embeddings at prediction time then make sure to use embedding.
- module =
embedding
If pure ranking accuracy is your goal, and you aren’t using embeddings for prediction then use:
- module =
ranking
Improving Cold Start Performance
If you are running a link prediction task with a lot of cold starts, consider running Kumo with the below option enabled. This tells Kumo to use data features as opposed to IDs for creating embeddings.
- handle_new_target_entities =
true
Additionally if you have a majority of cold starts from the entity table (e.g., a very high percentage of first time customers), you will want to configure this setting to instruct Kumo not to sample from the target table.
Increasing Link Prediction Embedding Dimension Sizes
If your dataset has text features or high cardinality categoricals, you might benefit from increasing the size of the embedding output.
- output_embedding_dim is set to
32by default; changing it to64or128could improve model performance
Updated 2 months ago