How can I improve the quality of my data?
General tips for ensuring data quality when creating graphs and executing pQueries and batch predictions.
Clean and Indicative Data
To ensure data quality, you should verify that the columns included in your Kumo tables contain accurate information with meaningful correlations to the prediction target.
Some tips on how to select columns:
-
Start by identifying all columns (from one or multiple tables) that might be related to or provide signals for predicting the target. This step marks an upper bound for the amount of information to ingest into Kumo.
-
As a quick first-level filter, you can remove redundant columns—columns that contain the same underlying information, but exist as multiple columns under one or multiple tables. For example, if you are a retailer with item sales data stored in two columns, one for per pound price values and the other for per kilogram price values, you should only include one of these columns to prevent redundancy.
-
Filter out columns where data is not actively maintained. For example, your company might have stopped collecting one type of data, but the column that stores historically collected data of that type still exists in your data store; or the definition of a column might have changed over time. Consult with the data owners/managers to confirm whether column names accurately describe their contents and are continuously updated.
-
Do not include columns that gets updated over time in a dimension table.
-
Check for formatting errors.
- Categorical data: check whether there are typos, extra spaces, inconsistent capitalization, etc.
- Numerical data: make sure that all values are entered as numbers instead of an English word (e.g., use “2” instead of “two”).
- Multi-categorical data: separators should be consistently used across relevant values. For example, if using "," as the separator in one entry, refrain from using ";" (or some other symbol) as a separator for other entries.
- Missing values: always leave fields with missing values completely blank—do not use strings or numbers like “null”, “N/A”, “-1”, etc.
Missing Data
Kumo identifies missing values as entries that are completely left blank, and will not treat columns marked by special strings such as "NaN" nor "none" as missing values. Missing values in numeric columns are also commonly filled with invalid numbers (e.g., -1); these entries should be left blank to be considered missing data.
If one feature column has a high percentage of data missing, you may want to find out whether it's possible to retrieve the missing values. If not, you should decide whether the percentage present is indicative enough to overcome the potential noise introduced by the missing values.
You can view the percentage of missing data per column by clicking on Column Statistics under your Table summary and looking at the "Missing" column.
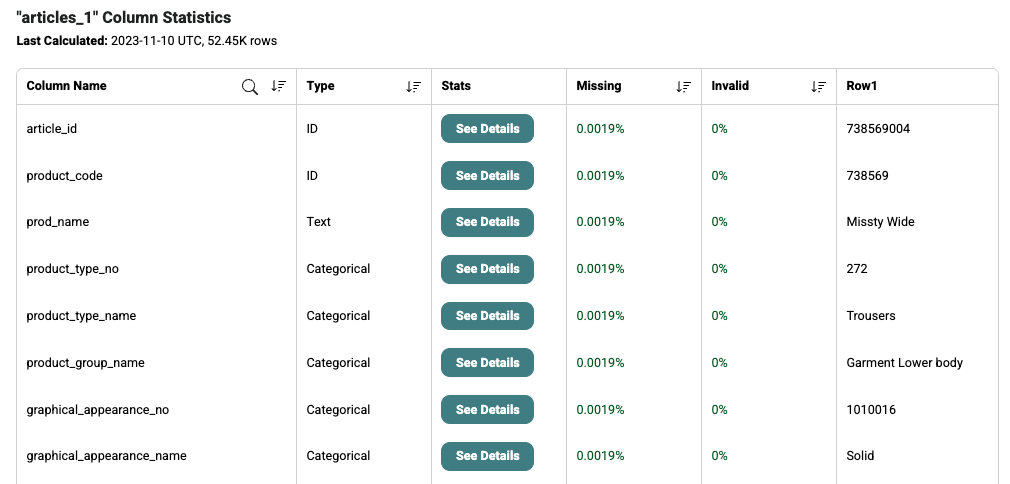
In some cases, you may want to keep a column with an abundance of missing values if the presence (or lack thereof) of a value in the column is an informative signal that the model can use for learning.
In general, a column should not be included if greater than 40% of data is missing at random. An exception to this is when the prediction target is a column in a dimension table (i.e., static); in this case, Kumo automatically views data points with missing target values as points for performing inference on. The percentage of missing values in the target column determines the training set and batch prediction output size, rather than being an indicator of data quality.
Learn More:
Updated 2 months ago