Detecting Chargeback Fraud
Solution Background and Business Value
Chargeback fraud is a common type of fraud encountered by e-commerce websites and other online retailers. The fraud occurs when a customer makes a purchase with their credit card, after the order/purchase is completed the customer disputes the transaction/order by issuing a chargeback request through their bank. If the chargeback is approved the transaction is cancelled and a refund is issued by the bank, depending on the payment method used the merchant might be accountable and the business incurs losses.
Building precise models which can identify this type of fraud in advance, and including these machine learning models in the fraud prevention operations cycle helps companies reduce the amount of fraud they encounter and be more successful in stoping fraudulent orders before they happen.
Data Requirements and Kumo Graph
Kumo GNNs can work with any dataset in a relational form, i.e. a collection of tables interconnected with primary and foreign key relationships. While it is possible to build a Kumo model with just a single table, we recommend starting with at least a few core tables which include the most important signals for a particular task. Our models leverage complex relationships between entities in the graph, along with their features to make accurate predictions, therefore we can use tables in their raw form and no feature engineering is necessary.
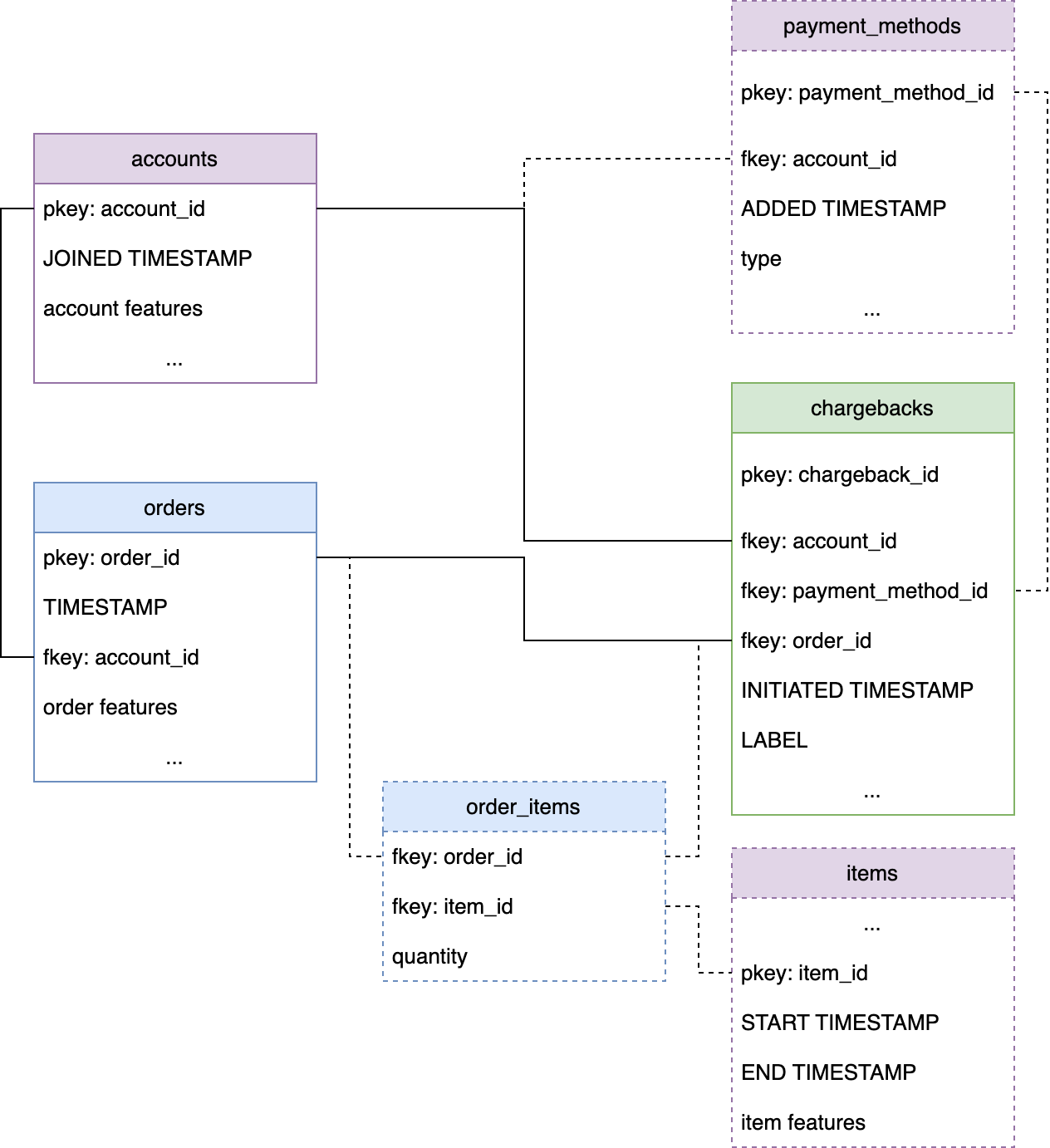
One example of a graph you might use for payback fraud detection. The dashed lines signify optional tables and connections.
Core Tables
At minimum we recommend starting with tables that include all the relevant entities and facts for the task at hand, for the case of chargeback fraud the entities are users/accounts which use our platform or participate in our marketplace, and the relevant events are orders and chargeback events.
- Accounts: the accounts table holds information about accounts/users/identities that participate in our marketplace. The table should include a unique
account_idprimary key, which connects it to other tables in the graph. The table may also include other account features, like account creation timestamp, age, location, etc. - Orders: the orders table holds information about the orders, if we want to connect it to other tables (e.g. to items which belong to this order) each order needs to include a unique
order_id, the table also needs to include a orderTIMESTAMP. We can include other order features if we have them, e.g. order location, total amount, payment method, etc. - Chargebacks: this is another table containing events, this table must include a
TIMESTAMPcolumn andchargeback_idcolumn. Depending on what other tables we include in our graph it can also include many fkeys, which we can connect with other tables (e.g. see above example graph), we can also include other relevant fields if we have them available. Finally, since our goal is to predict fraud, the chargebacks table needs to include aLABELcolumn which signifies if a chargeback was fraudulent or not.
Additional Table Suggestions
If we have additional data available we can easily extend the above core tables by including additional tables in the graph. Here are some suggestions of which tables we can also use:
- (optional) items and order_items: The items purchased might hold important signal for fraud detection. Since the relation between orders and items is many-to-many we need an additional order_items table connecting orders and items.
- (optional) payment methods: We can associate each account with a payment method and connect this table with the chargebacks table
- (optional) merchants
- (optional) account_events
Predictive Query
We can approach detecting chargeback fraud from many aspects, the most natural is at the chargeback level, in this case our model predicts if each chargeback is fraudulent or not based on the provided labels of past chargebacks provided:
PREDICT chargebacks.LABEL
FOR EACH chargebacks.chargeback_idWhen we want to make predictions for new chargebacks we just leave the LABEL column empty and run batch predictions. This approach works well if we want to build an automated system to classify chargebacks as they occur. Alternatively this same query can be used at the order level, but we need to move the LABEL column into the orders table in above graph formulation, this way we can use the query:
PREDICT order.LABEL
FOR EACH order.order_idWe might also be interested in producing risk scores at the user or order level, these scores can be produced in advance and used in a preventive way (e.g. triggering a order review when it happens in real time for high risk orders). Luckily the PQ Language is very flexible and allows us to easily define temporal queries as well, where the target is an aggregation of events over a future timerange, in this case we can predict if each user or order will be associated with at least one fraudulent chargeback in the following X days:
-- For each order_id, assuming that a chargeback exists, predict if it is fraudulent or not
PREDICT FIRST(chargebacks.LABEL = 1, 0, X) > 0
FOR EACH orders.order_id
ASSUMING COUNT(chargebacks.*, 0, X) > 0
-- For each account_id, assuming that it has more than 0 orders associated with it,
-- predict if the user will make at least one fraudulent chargeback
PREDICT COUNT(chargebacks.LABEL = 1, 0, X) > 0
FOR EACH accounts.account_id
ASSUMING COUNT(orders.*, 0, X) > 0Deployment
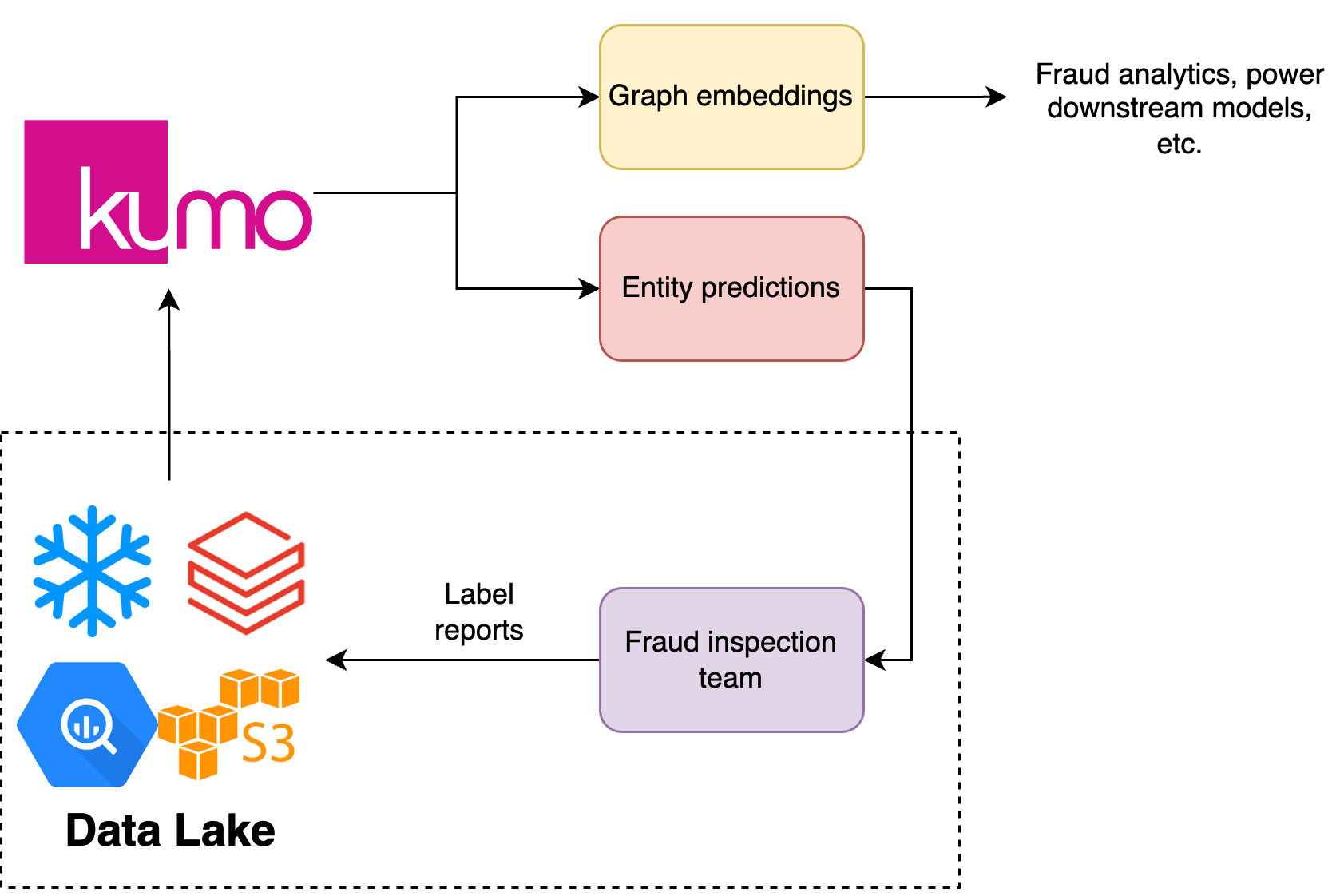
The deployment of fraud detection ML models heavily depends on the maturity of the fraud detection system. Given that fraud machine learning tasks are most commonly heavily imbalanced binary classifications that require tedious labelling of examples, models which make good predictions with relatively few labels provide huge operational cost savings. Since Kumo models use both entity features as well as the relational context they enable us to get started with very few examples. Moreover, due to the adaptive nature of fraudsters, fraud detection systems almost always become human and ML system hybrids, with human fraud teams/analysts continually labelling new examples as fraudulent or not. The deployment of machine learning models heavily depends on the maturity of our fraud detection system.
When we are just starting out with very few labels we can use ML models to inform our fraud team and make them more efficient. For chargeback fraud we produce predictions at a chargeback level in a batched fashion. We can then use the ML model outputs to prioritise which chargeback events require labelling by defining a scoring strategy. This makes the human component of the system more efficient and allows us to more quickly move towards the next stage which is using automated systems to stop fraud from happening. We can transition towards the second stage of deployment once we’ve accumulated enough labels for our models to be precise enough to deploy automatically, the purpose of the human team at this stage shifts towards maintaining the system and discovering/labeling new kinds of attack vectors that the model misses by looking at the false negatives.
Updated 2 months ago