MLOps and Monitoring
Out of the box anomaly detection and alerting.
Introduction
Machine Learning Operations, commonly known as ML Ops refers to the tools and practices to manage and automate ML model lifecycles in production. It integrates DevOps principles, ensuring accurate, effective, and business-aligned ML solutions. This article explores how Kumo assists organizations to navigate their ML lifecycle and makes the path to production as seamless as possible. Kumo has several capabilities and tools that can be aligned with the important components of ML Ops.
Kumo's ML Ops Architecture
ML Ops started as a set of best practices, but now is evolving into an independent approach to entire ML lifecycle: data management, model generation, version control, automation, model deployment and monitoring while focussing on business and regulatory requirements. Kumo's architecture of ML Ops includes a data connecting platform where input data is ingested, predictive query interface where models are constructed and a model monitoring platform. Kumo has ML Ops tools orchestrating the movement of ML models, data and outcomes between the systems. In this article we group Kumo's ML Ops processes into three primary components: data management, model production orchestration, and model monitoring as represented in the figure below.
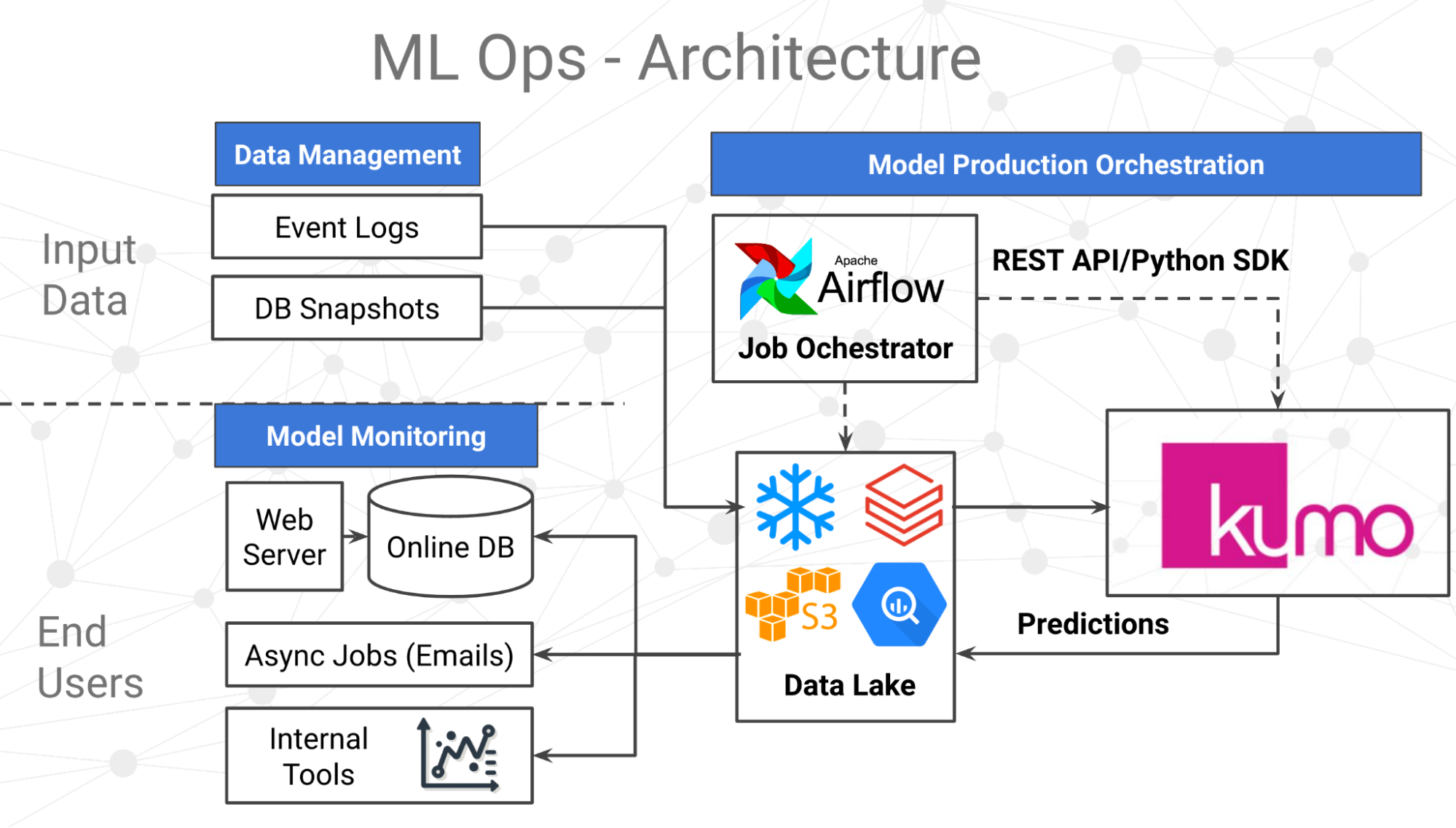
The following table provides a brief summary of the ML Ops capabilities within Kumo. These capabilities help organizations navigate through their ML journey.
Category | Kumo Capabilities |
|---|---|
Data Management | DB snapshot, column name, data type, missing and invalid percentage |
Model Production Orchestration | Graph link health |
Model Monitoring | Batch prediction monitoring dashboards* |
Data Management
Data management is an important component of ML Ops from the perspective of data usability in model development and reproducibility of model. Kumo allows users to ingest data from a variety of data sources including Snowflake, S3, BigQuery, and Databricks (see connect tables for more details). Kumo displays a set of warnings during table creation such as duplicate primary key, uniform column, missing etc. This allows users to make decisions whether the data can move to the next step of model generation. Kumo allows users to view the data information such as column name, data type, missing percentage and invalid percentage along with the summary statistics of each column. The statistics for categorical datatype include total count, unique, missing percentage and mode along with the histogram.
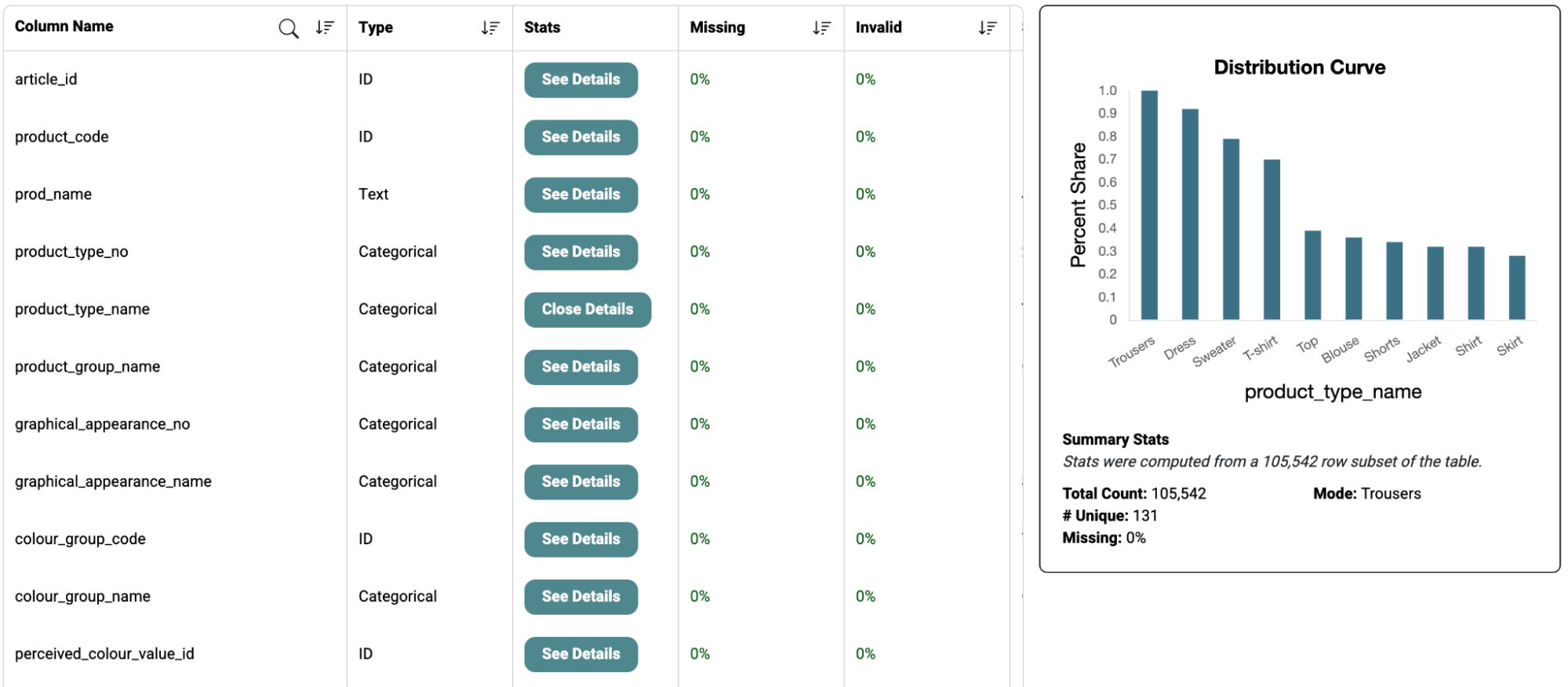
Summary statistics for numerical datatype include total count, number of unique, missing percentage, mean, min, max, 25th percentile, 50th percentile, 75th percentile along with the distribution curve.
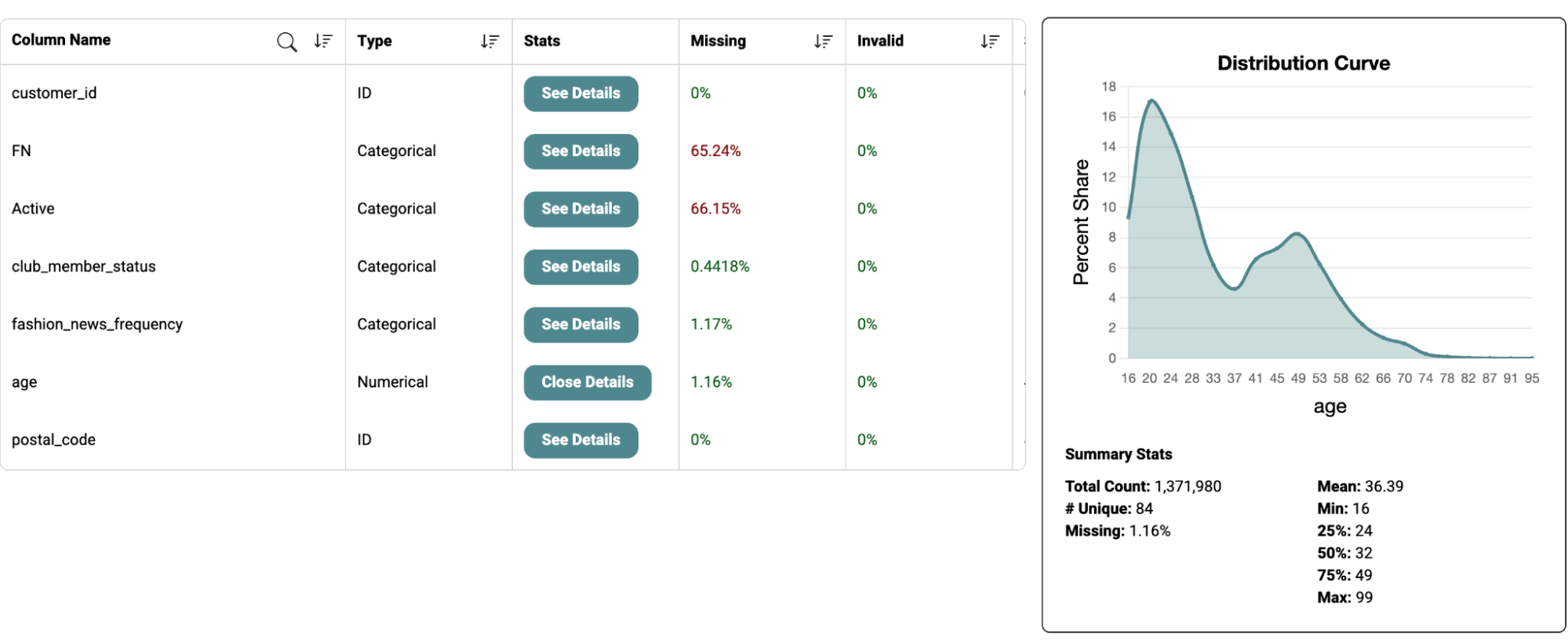
This provides adequate information to the users to determine if the data can be used in the model development process.
Data versioning: Data versioning is important for model reproducibility. Kumo allows users to version control and write descriptions related to the data during the data ingestion process. Kumo displays the time stamp of each data update.
Data governance: Data governance is an important feature of ML Ops from a regulatory perspective. Customers only access Kumo via this Predictive Query interface. ML predictions are returned via the Customer’s Data Store. All customer data remains stored in the Customer’s Data Store. Predictive queries defined by users are run against the Cache, which is populated from the Customer's Data Store. What data resides in the Cache and the Cache retention time are both configurable by the customer. The customer must provide Kumo credentials/access policies in order for Kumo to access (a subset of) the Customer’s Data Store. See data security for more details.
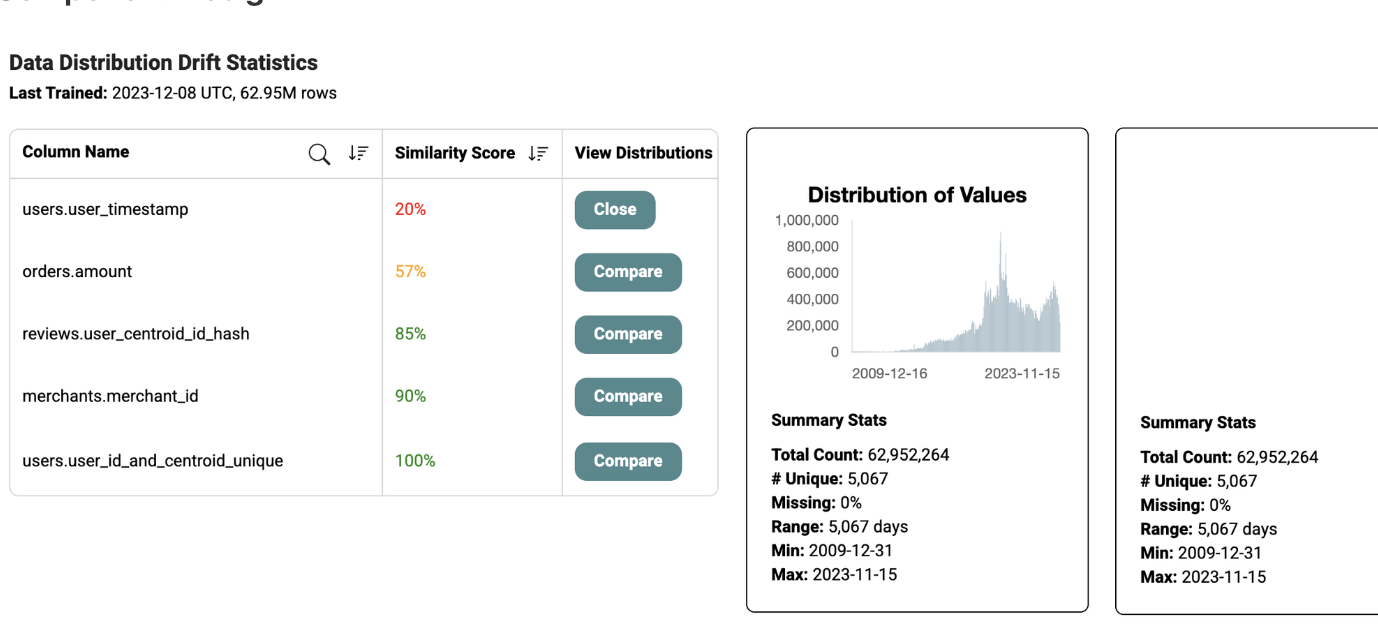
Data monitoring*:Kumo helps users identify data drift (changes in the statistical properties of the data over time). Below is a snapshot of the data distribution drift statistics available in Kumo's platform. It consists of a similarity score and a comparison of column distribution.
Model Production Orchestration
This section elaborates how Kumo helps organizations achieve key goals of ML Ops such as model generation, reproducibility and model diagnostics. Kumo's model production orchestration encompasses the entire process of model generation including creating graph links, pQueries, model evaluation, batch predictions.
Link Graphs
Once the tables are ingested, Kumo interface allows users to link graphs with ease. This part is crucial, since the linkages allow Kumo to derive the necessary input signals for accurate predictions. Kumo displays "Graph link health" to users to identify potential issues with the linkages. This information helps users decide if they can move to the next step of developing the pQueries. Please see link graphs for more details on linking graphs.

Create PQueries
Once the link graph process is complete, Kumo allows users to create the PQueries to start developing their ML models. See create pQueries for more details. Kumo's User interface allows users to train Predictive Queries with ease. Kumo has the Python SDK to define the graph and Predictive Query as code and import it into the repository. Regardless of approach, Kumo will allow users to quickly iterate until they find the the problem formulation that delivers the best performance. See seamless workflow from raw logs to production for more details. Kumo gives users the flexibility to store adequate information about each pQuery run. In addition, under each graph link, the associated pQueries which are run using the links are listed. Below is a snapshot of the different pQueries which are run using the same graph link and the associated status, runtime, timestamp when created and last trained information. This allows users to version control and retrieve the historical PQueries for reproducibility.

Model Evaluation
Kumo has a comprehensive array of evaluation metrics designed for thorough model diagnostics. These evaluation metrics provide insights into the model run and offer a general overview of the model's performance. The following evaluation metrics are displayed in the Kumo platform.
Binary Classification: ROC Curve, Precision Recall Curve, Cumulative Gain Chart, Confusion Matrix, AUPRC, AUROC, Label distribution over time(found this in MRM document)
Regression: Predicted vs Actual Plot, Distribution Histogram, MAE, MSE, RMSE, SMAPE, Label distribution over time
Multiclass: Average Precision, AUPRC, Recall for each label and across all classes, Label distribution over time
Link Prediction: F1, MAP, PRECISION, RECALL @ k
Below is a snapshot of the evaluation metrics for a binary classification model. For more information see Review Evaluation Metrics
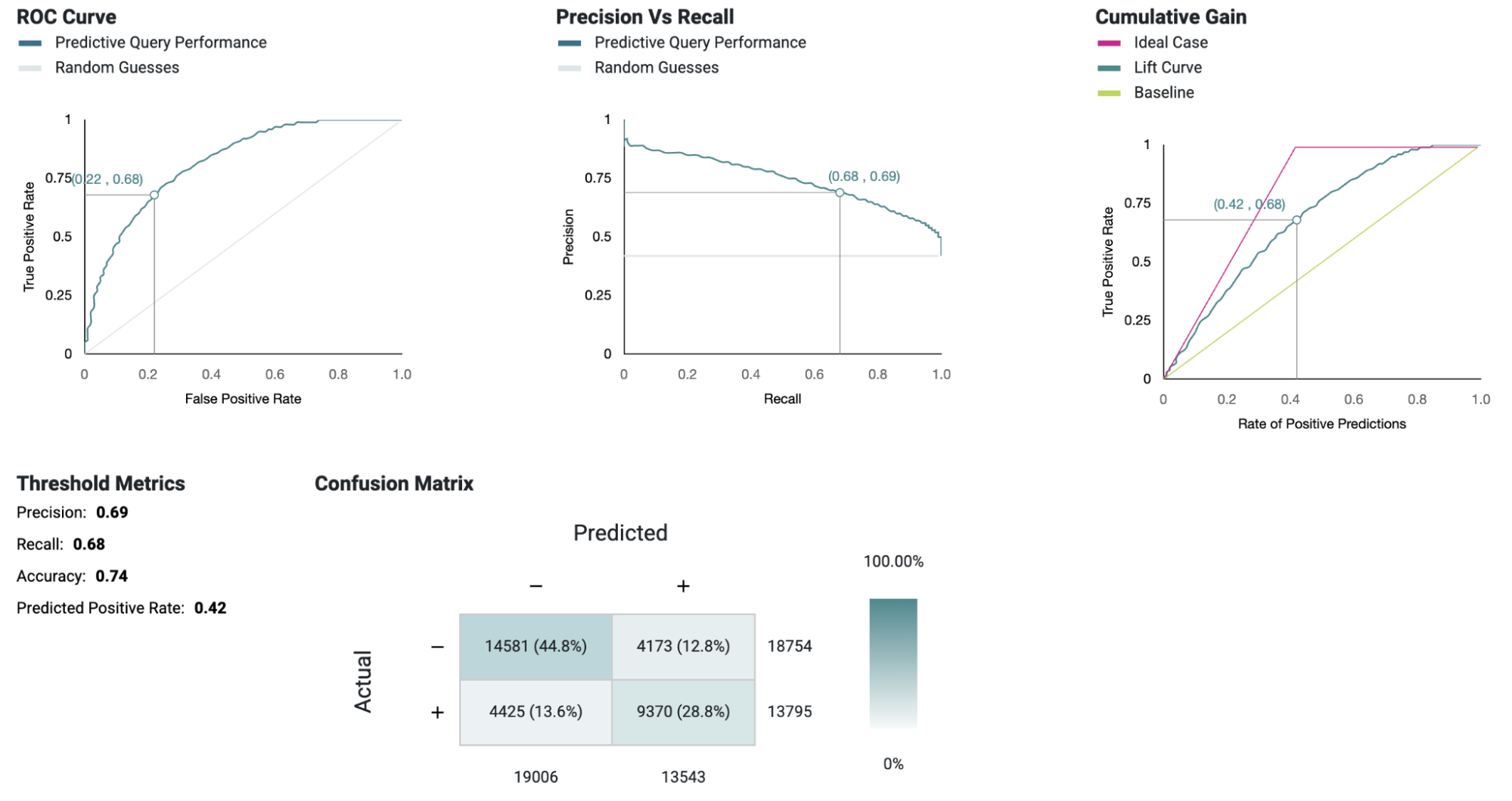
Kumo predictions can be orchestrated as part of the automatic workflow. However, it is recommended to check the statistics returned by the API, before promoting a new set of predictions in production.
Batch Predictions
Once user is comfortable with the evaluation metrics and how well the pQuery is working on the historic data, the ML model is ready for batch predictions. Each batch prediction represents a particular run of the selected pQuery, and results in the creation of a table with the entity primary key IDs, the anchor time of the prediction and the prediction output. For more details see create batch predictions. Kumo gives users the flexibility to export the batch predictions to various data environments and local workspaces.
Model Monitoring
Monitoring is an integral part of ML Ops that ensures the ongoing performance and reliability of ML models in production. Kumo's platform facilitates model monitoring, rapid issue resolution, and continuous improvement in the model's effectiveness.
Batch Prediction Monitoring
Kumo allows recurring batch prediction jobs(e.g. on a daily basis) using the same pQuery. Additionally, Kumo helps users monitor job status for running queries and predictions and view evaluation metrics when completed. See productionize for more details. Kumo enables users to download the statistics and prediction scores associated with each batch prediction job in the UI and public API. Users can maintain a repository of each batch prediction run and monitor the deviations in the statistics. The API also provides flexibility to cancel pQueries and predictions. In the Airflow workflow, users can implement logic to optionally halt the workflow if the warnings exceed acceptable thresholds. This is an easy way to prevent new predictions from reaching production if needed.
Kumo platform displays batch prediction monitoring dashboards for each job creation date. The dashboards display details on the count, distribution and evaluation metrics for each job creation date. Kumo also displays the list of batch prediction jobs for a pQuery. This enables users to maintain a repository of the different batch prediction jobs associated with a pQuery.
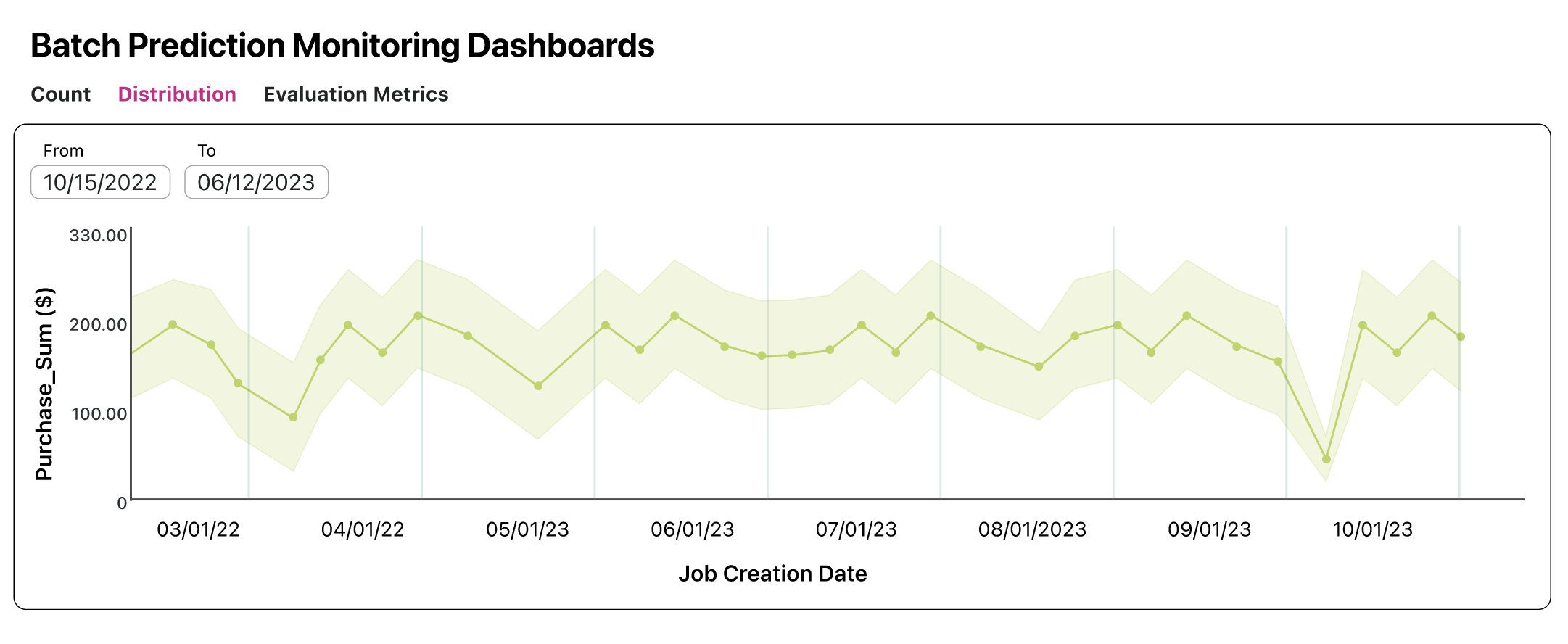
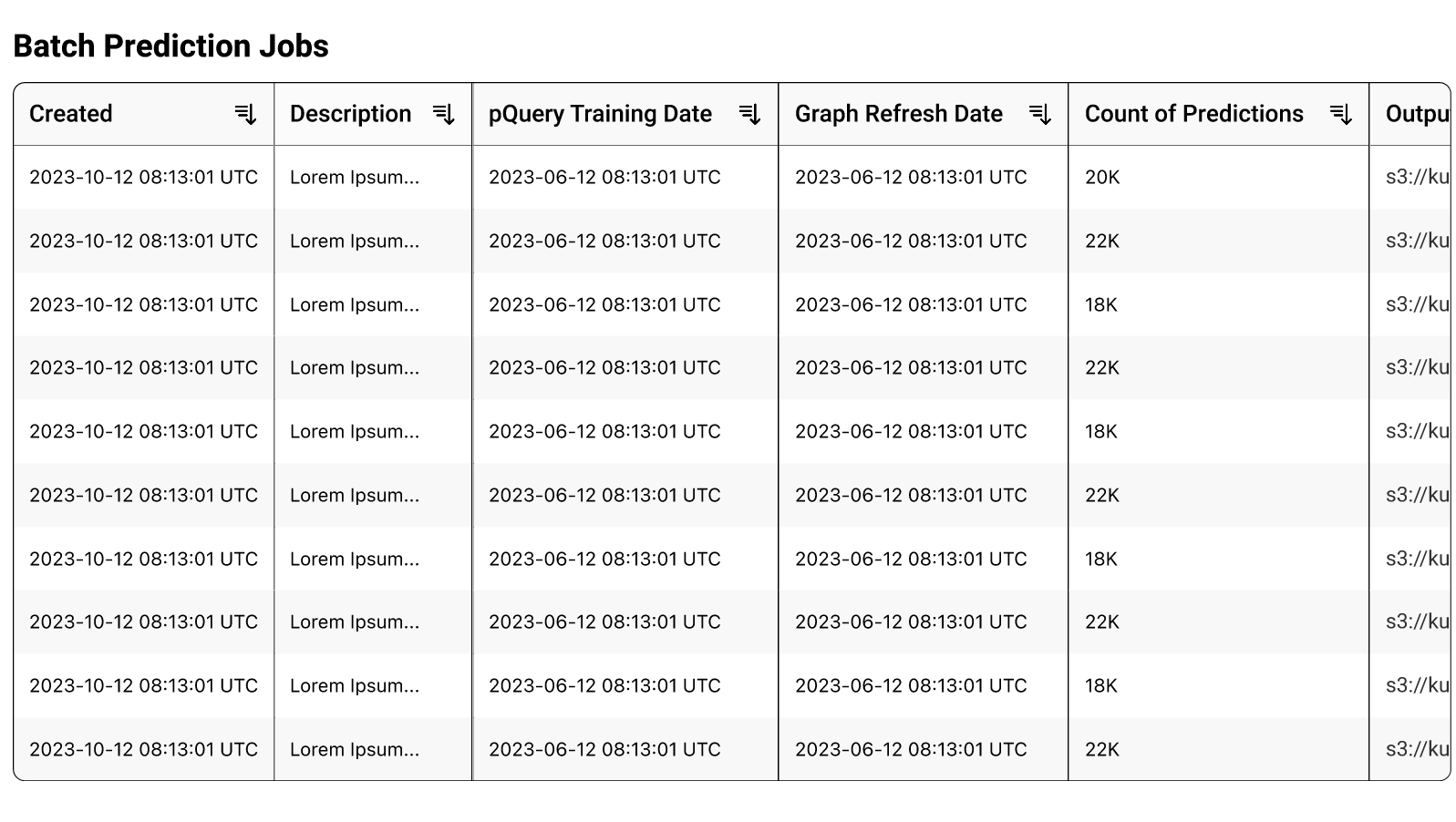
Model Retraining
Kumo's REST API allows users to retrain the same pQuery on new data. Model retraining is essential for keeping ML models relevant, accurate and adaptable to the dynamic nature of the data and real world conditions. It allows the model to adapt to shifts in user behavior, external factors etc. ensuring it remains relevant and effective. Kumo provides a platform to retrain the models with ease. If a model is required to be retrained on a regular basis the key model performance statistics can be retrieved through the public API. These metrics can be automatically consumed within the production workflow and can be exported into the monitoring platform of choice (DataDog , Grafana etc.).

Email Alerting*In the near future, Kumo will have the an additional capability to send email alerts for anomalies, which can be easily forwarded to the relevant alerting solution (eg., Pagerduty). Kumo will allow users to setup thresholds and alerts for deviations in critical metrics to trigger timely interventions. If the monitoring pipeline can identify model performance issues, it will generate triggers to alert the relevant stakeholders. These alerts will have configurable thresholds, such as:
- Alert if average prediction drops by X%
- Alert if evaluation metric accuracy change by Y%
- Kumo is currently under the process of establishing an automatic alerting system on key metrics to alert stakeholders of any drift or troubleshoot.
Conclusion
Kumo assists organizations to navigate their ML lifecycle and makes the path to production as seamless as possible. Kumo has several capabilities and tools that are aligned with the important components of ML Ops: data management, model generation, version control, automation, model deployment and monitoring while focussing on business and regulatory requirements. These capabilities make Kumo an advantageous choice for businesses.
*This feature will be available soon.
Updated 2 months ago